
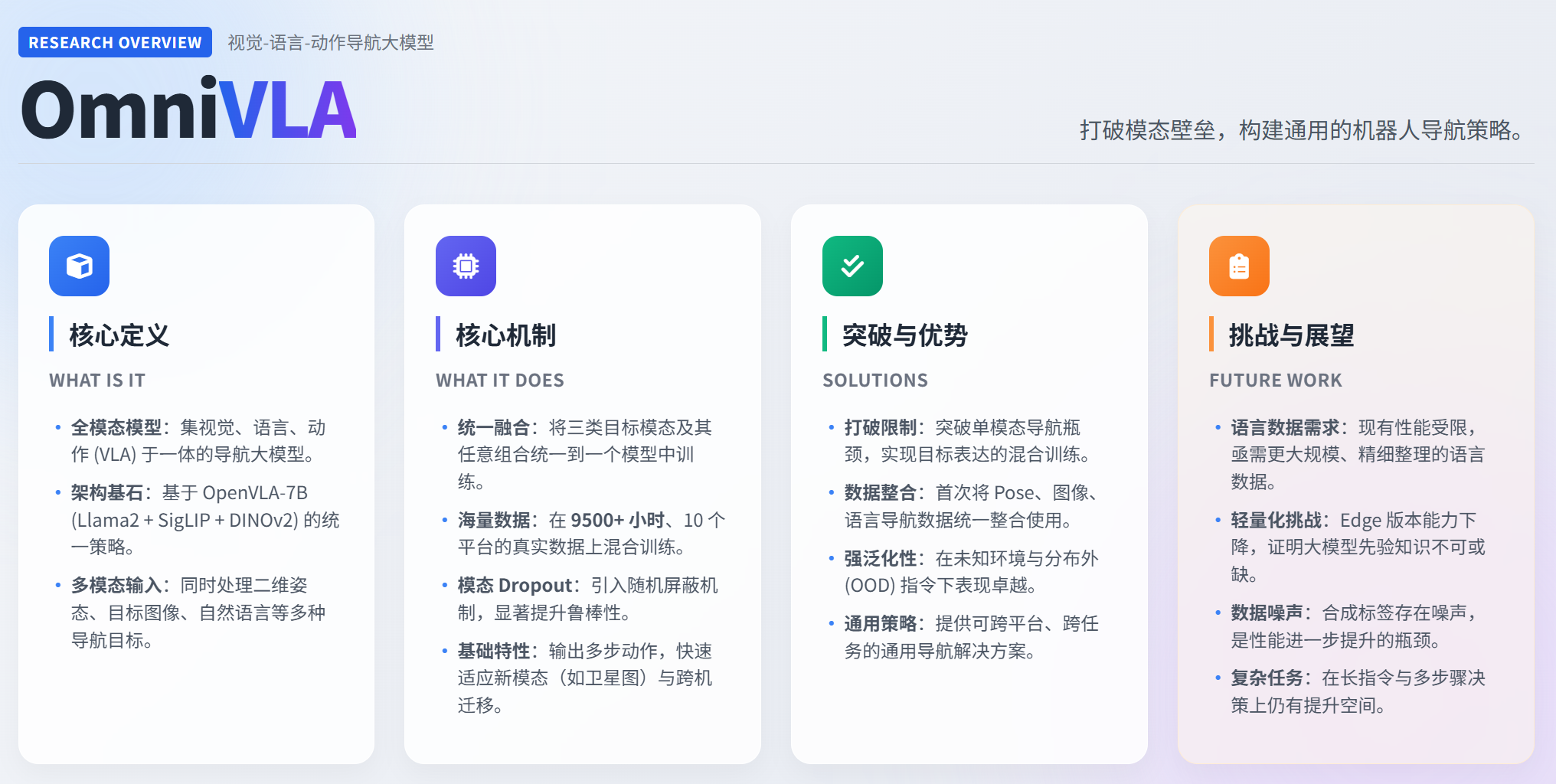
一、是什么(What is it)
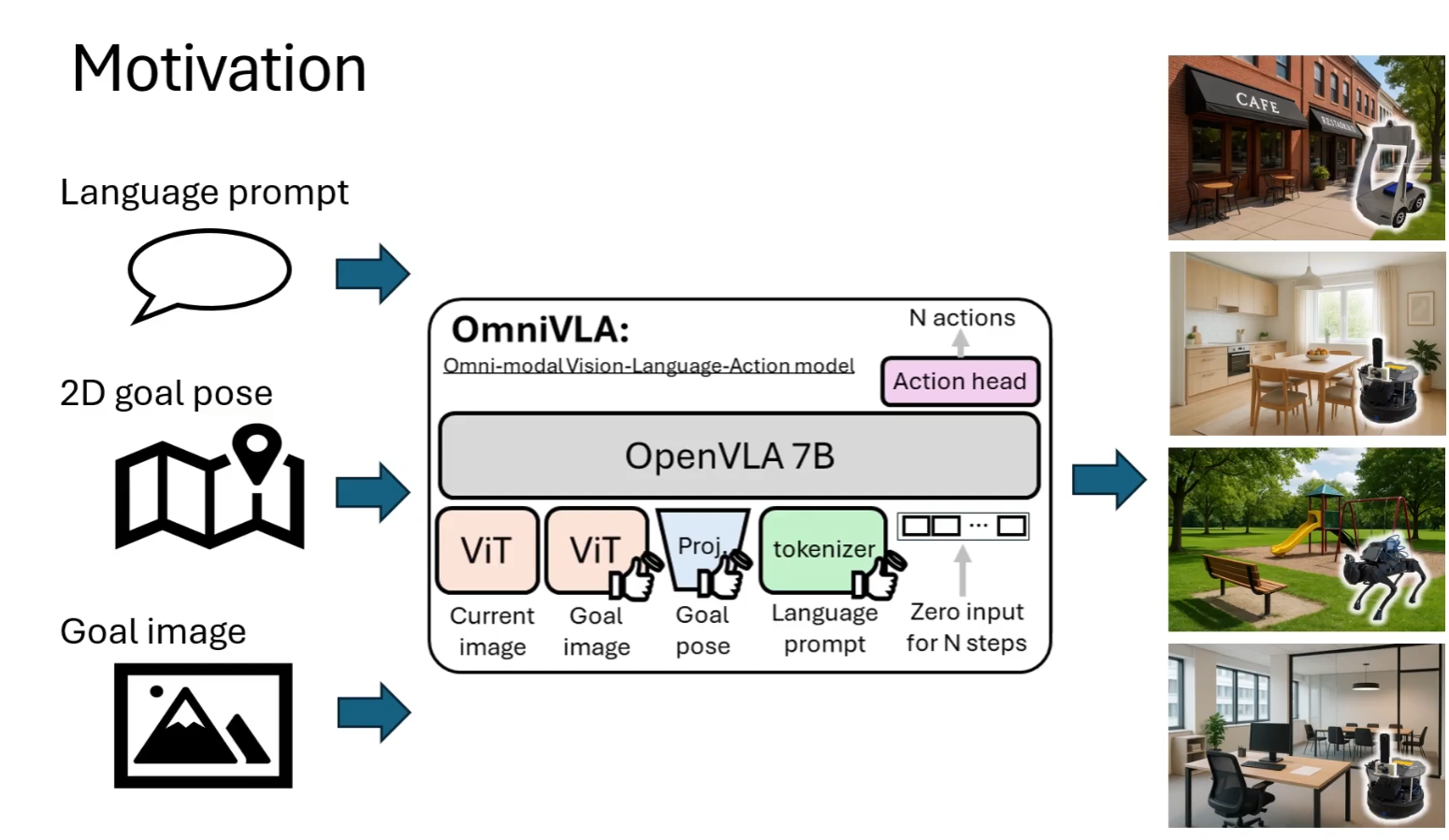
- 一个 全模态视觉-语言-动作(VLA)导航大模型。
- 基于 OpenVLA-7B(Llama2-7B + SigLIP + DINOv2) 的统一策略模型。
- 能同时处理 二维姿态、目标图像、自然语言 等多种导航目标模态。
二、它能干什么
不需要全局地图,也不做 SLAM,不规划全局路径,通过用语言描述,gps目标位置,目标位置的图像这三者中的任意一个或组合,就能实现机器人的导航。
1. Language-conditioned navigation 基于语言指令的导航
没有 goal pose、没有目标图像,通过语言进行描述
- 前往左侧白色墙后面的深绿色沙发
2. Multi-modal conditioned navigation (Language & 2D pose)多模态条件导航(语言 + 2D 位姿)
目标位置(goal pose)是通过 GPS/2D 坐标给机器人的,画面里看不到
- 沿着棕色小路的中间行进
3. 2D goal pose-conditioned navigation 基于 2D 目标位姿的导航
没有语言,没有目标图像,也不需要语义理解,只有目标位置(goal pose)。
4. Egocentric goal image-conditioned navigation 基于第一视角目标图像的导航
目标由一张“目标图像”提供,机器人要走到“看起来像目标图像”的地方。
与传统方法对比:
| 传统机器人 | 大模型导航 (VLM/VLA) |
|---|---|
| 必须定位(SLAM) | ❌ 不需要 |
| 必须建图 | ❌ 不需要 |
| 必须规划全局路径 | ❌ 不需要 |
| 依赖几何 | ✔ 依赖视觉语义与行为先验 |
| 显式建模 | ✔ 隐式学习世界规律 |
| 规则驱动 | ✔ 数据驱动 |
① 视觉模型(DINOv2 / SigLIP)懂世界语义 和 SLAM 不同,视觉模型能“理解”场景。
② 大语言模型(LLM)提供世界知识与推理结构 比如“经过立柱后到入口”,模型能理解“after passing”。
③ 大规模跨平台机器人数据(9,500 小时)提供行为分布 机器人在各种真实场景中“看过 / 走过 / 绕过”。
这让模型具备了:世界理解 + 行为策略 + 常识导航能力
三、创新点
- 将三类目标模态及其任意组合统一到一个模型中训练。
- 在 9500+ 小时、10 平台 的大规模真实导航数据上混训。
- 引入 模态 Dropout:随机屏蔽不同模态,提升鲁棒性与泛化能力。
- 输出 多步动作序列。
- 展现基础模型特性:可快速适应新模态(如卫星图)、可跨机器人迁移。
四、解决了什么问题(What problems it solves)
- 打破单模态导航的限制(过去模型无法混合训练不同目标表达)。
- 统一多数据集训练,让 pose、图像、语言导航数据第一次可整合使用。
- 显著提升未知环境与 OOD 指令下的泛化能力。
- 提供一个可跨平台、跨任务的 通用导航策略
五、还有什么不足(Limitations)
- 语言导航性能仍有限,需要更大规模、精细整理的语言数据。
- 轻量版 OmniVLA-edge 的语言能力不足,说明大模型视觉-语言先验不可或缺。
- 合成标签数据存在噪声,可能成为进一步提升的瓶颈。
- 仍需改进在“复杂长指令”“多步骤任务”中的理解和决策质量。
六、完整系统架构总览
6.1 总览
6.2 系统组成结构

模块详细清单:
| 分类 | 模块编号 | 模块名称 | 功能说明 |
|---|---|---|---|
| **核心模型 ** | 1 | Vision Backbone | SigLIP + DINOv2 视觉双编码器,提取图像特征 |
| 2 | Vision Projector | MLP,将视觉特征投影到 LLM 维度(1152→4096) | |
| 3 | Proprio Projector | MLP,将 2D 目标位姿(x,y,θ)投影到 LLM 维度(4→4096) | |
| 4 | Tokenizer + Embedding | 文本分词,生成语言 token | |
| 5 | LLM(Llama-2 7B) | 70 亿参数语言模型,作为核心推理引擎 | |
| 6 | Action Head | MLP / ResNet,输出 N 步动作序列 | |
| 辅助模块 | 7 | MBRA | 遮蔽重标注模块,用于训练数据动作修正 |
| 8 | FiLM | 语言-视觉调制融合模块(可选,默认关闭) | |
| 数据处理 | 9 | 数据集加载器 | 支持 GNM、LeLaN、FrodoBots、BDD、CAST 等五大数据集 |
| 10 | 图像预处理 | Resize、归一化、通道调整 | |
| 11 | 数据增强 | 图像扰动、裁剪、畸变(训练时) | |
| 12 | 动作归一化 | BOUNDS_Q99(95) 方法,将动作压缩到 [-1,1] | |
| 训练模块 | 13 | 损失函数 | L1 动作损失 + 语言模型损失 |
| 14 | 优化器 | AdamW(lr=1e-4) | |
| 15 | 学习率调度 | Warmup + 线性衰减(10 万步) | |
| 16 | LoRA | Rank=32,高效微调 | |
| 17 | 分布式训练 | DDP,多卡并行训练 | |
| 推理模块 | 18 | 传感器接口 | 摄像头、GPS、IMU 输入 |
| 19 | 图像预处理(推理) | GPU 加速,支持 BF16 / FP16 | |
| 20 | 安全模块 | 碰撞检测、速度限制、安全半径 | |
| 21 | 机器人控制 | 速度/角速度命令发送、底盘控制 |
6.3 数据流
(1) 训练

(2) 推理
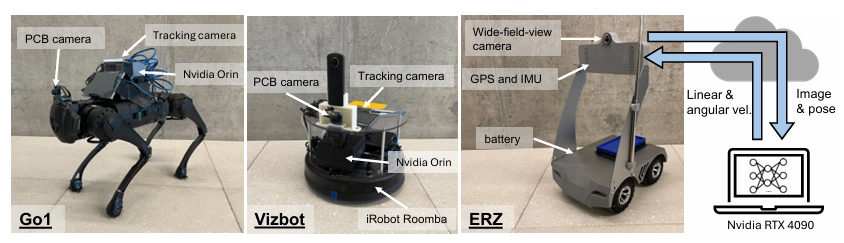
机器人的平台概览

评论
加入讨论
登录或注册后即可发表评论,与其他学习者交流
0 条评论
加载评论中...