
对应代码:
include/al/和src/al/全部文件 目标:理解如何将约束"塞进"代价函数,并组装完整的双层循环求解器 前置知识:Chapter 3(iLQR)、Chapter 4(约束建模)
增广拉个朗日示意图:
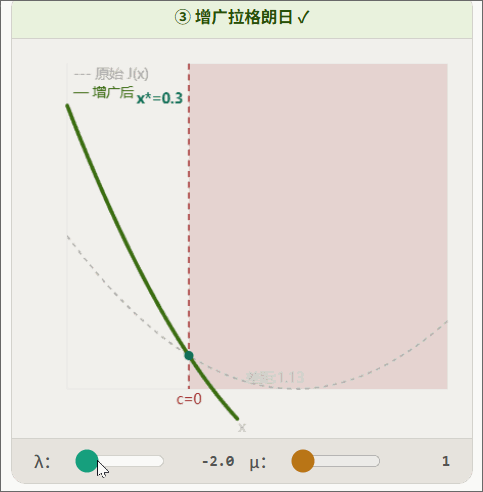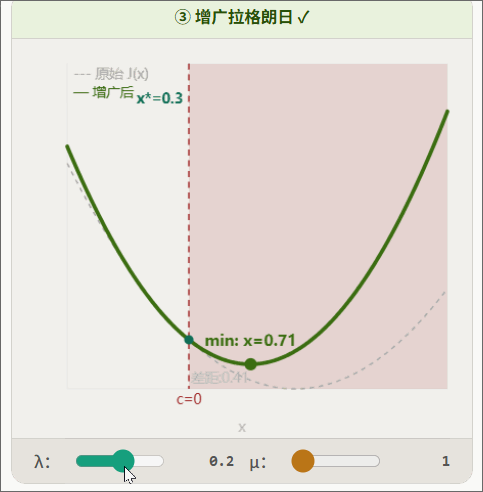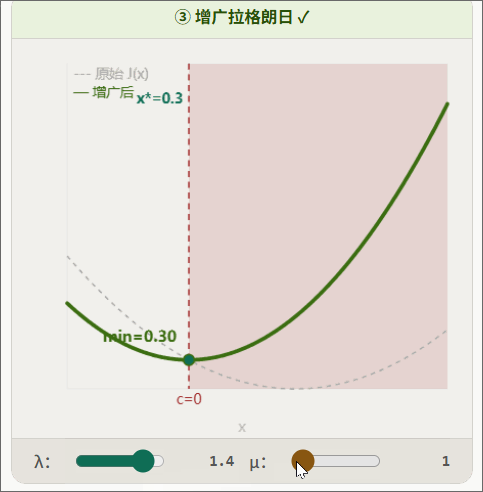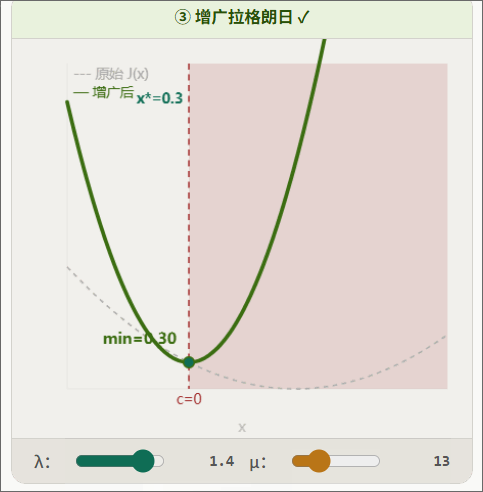
5.1 从 iLQR 到 AL-iLQR:为什么需要增广拉格朗日?
回顾一下我们目前的处境:
| 已有能力 | 来源 | 缺少什么 |
|---|---|---|
| 求解无约束非线性轨迹优化 | Chapter 3 iLQR | 无法处理约束 |
| 建模各种约束(控制量、速度、道路边界、障碍物) | Chapter 4 约束接口 | 约束只是"定义"了,iLQR 不知道它们的存在 |
iLQR 的 backward pass 和 forward pass 里没有任何约束信息——它只看代价函数和动力学。那如何让它"尊重"约束?
核心思路很简单:把约束变成代价的一部分。违反约束?让你付出"天价"代价。约束满足?不额外收费。这样,iLQR 在优化代价时,自然会倾向于满足约束。
但"惩罚项"怎么设计?这就是增广拉格朗日方法(Augmented Lagrangian, AL)要解决的问题。
5.2 约束处理方法对比:从暴力到优雅
在正式引入 AL 之前,我们先看看有哪些"把约束变成代价"的方法,以及为什么 AL 是最好的选择。
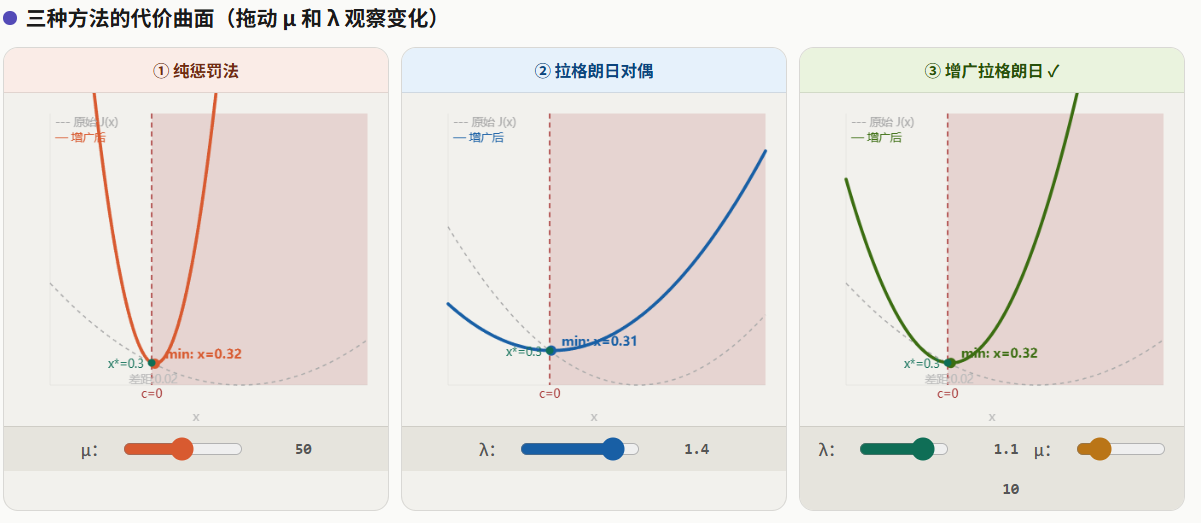
5.2.1 方法一:纯惩罚法(Penalty Method)
最直觉的想法——违反约束就罚钱:
是惩罚力度。约束违反越大,二次罚项越大。
优点:简单粗暴,容易实现。
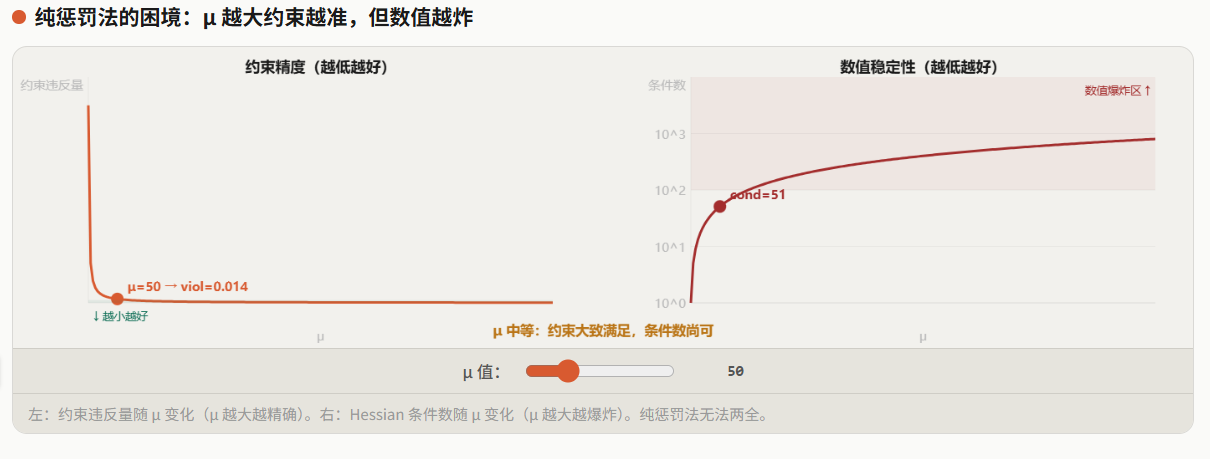
致命缺点:要让约束"精确"满足, 必须趋向无穷大。但 太大会导致:
- 代价函数的 Hessian 矩阵条件数爆炸,数值求解变得极不稳定
- iLQR 的 backward pass 中 变得病态,Cholesky 分解失败
5.2.2 方法二:拉格朗日对偶法(Lagrangian Dual)
引入拉格朗日乘子 :
的物理含义是约束的"价格"——每违反一单位约束,代价增加 单位。 优点:理论上 收敛到最优乘子时,不需要无穷大的惩罚就能精确满足约束。 缺点:纯对偶法需要求鞍点(对 求最小、对 求最大),不适合直接用 iLQR 这样的无约束求解器。
5.2.3 方法三:增广拉格朗日法(本项目采用)
AL = 拉格朗日 + 惩罚,取两者之长:
为什么这是最佳选择?
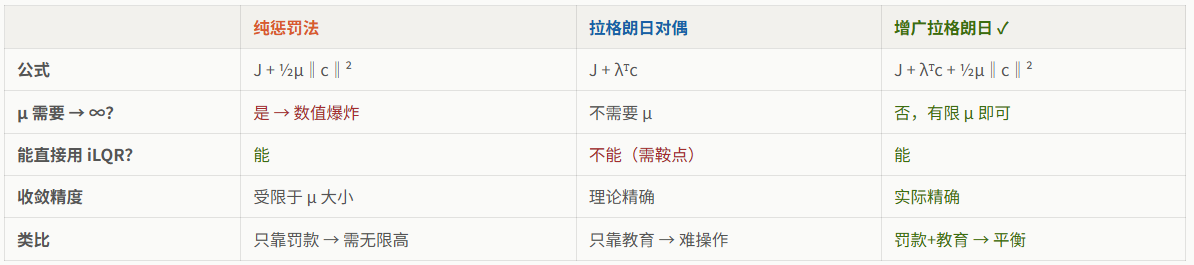
| 特性 | 纯惩罚法 | 纯对偶法 | 增广拉格朗日 |
|---|---|---|---|
| 需要趋于 ? | 是 → 数值爆炸 | 不需要 | 否, 收敛后 有限即可 |
| 能直接用 iLQR? | 能 | 不能(需要鞍点) | 能(固定 ,只对 求最小) |
| 收敛精度 | 受限于 大小 | 理论精确 | 实际精确(有限 即可) |
| 实现复杂度 | 低 | 高 | 中等 |
5.3 增广拉格朗日数学原理
5.3.1 等式约束的 AL 项
对于等式约束 ,增广拉格朗日函数中对每个约束分量 添加的项为:
- :拉格朗日乘子(对偶变量),表示第 个约束的"价格"
- :惩罚参数,控制惩罚强度
- :线性项,来自拉格朗日对偶,提供梯度方向
- :二次惩罚项,提供曲率,帮助收敛
直觉:想象 是一维的。 是关于 的二次函数,其最小值点在 。当 逐渐收敛到最优值时,这个最小值点会趋近 ,也就是约束被精确满足。
5.3.2 不等式约束的 AL 项
不等式约束 需要特殊处理。关键区别:当约束远未活跃()时,不应该施加任何惩罚。
公式为:
为什么要用 ?分三种情况理解:
情况 1:约束远未活跃(,比如车辆离障碍物很远)
当 (初始状态),。不施加任何惩罚——车辆离障碍物很远,何必操心?
情况 2:约束刚好活跃(,车辆刚好在安全边界上)
小惩罚。约束在边界上, 的存在让优化器知道这个约束是"活跃的"。
情况 3:约束被违反(,车辆侵入了障碍物区域)
大惩罚! 既有二次惩罚(),又有线性惩罚()。
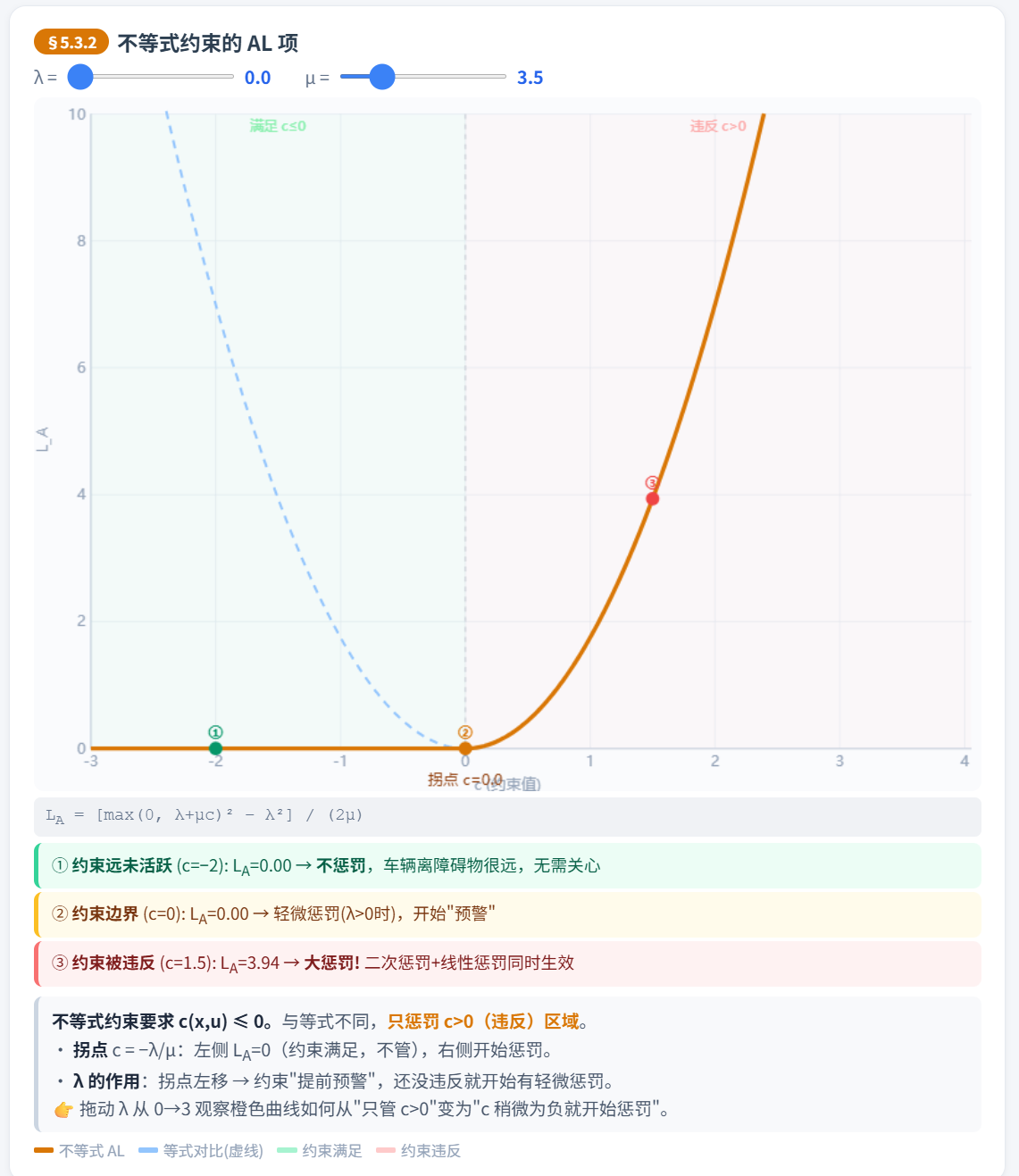
对比等式约束:等式约束的 AL 项是关于 的完整抛物线(两侧都惩罚)。不等式约束的 AL 项只惩罚右半部分(),左半部分被 截断为零。这正是不等式约束的语义: 是允许的,只有 才需要惩罚。
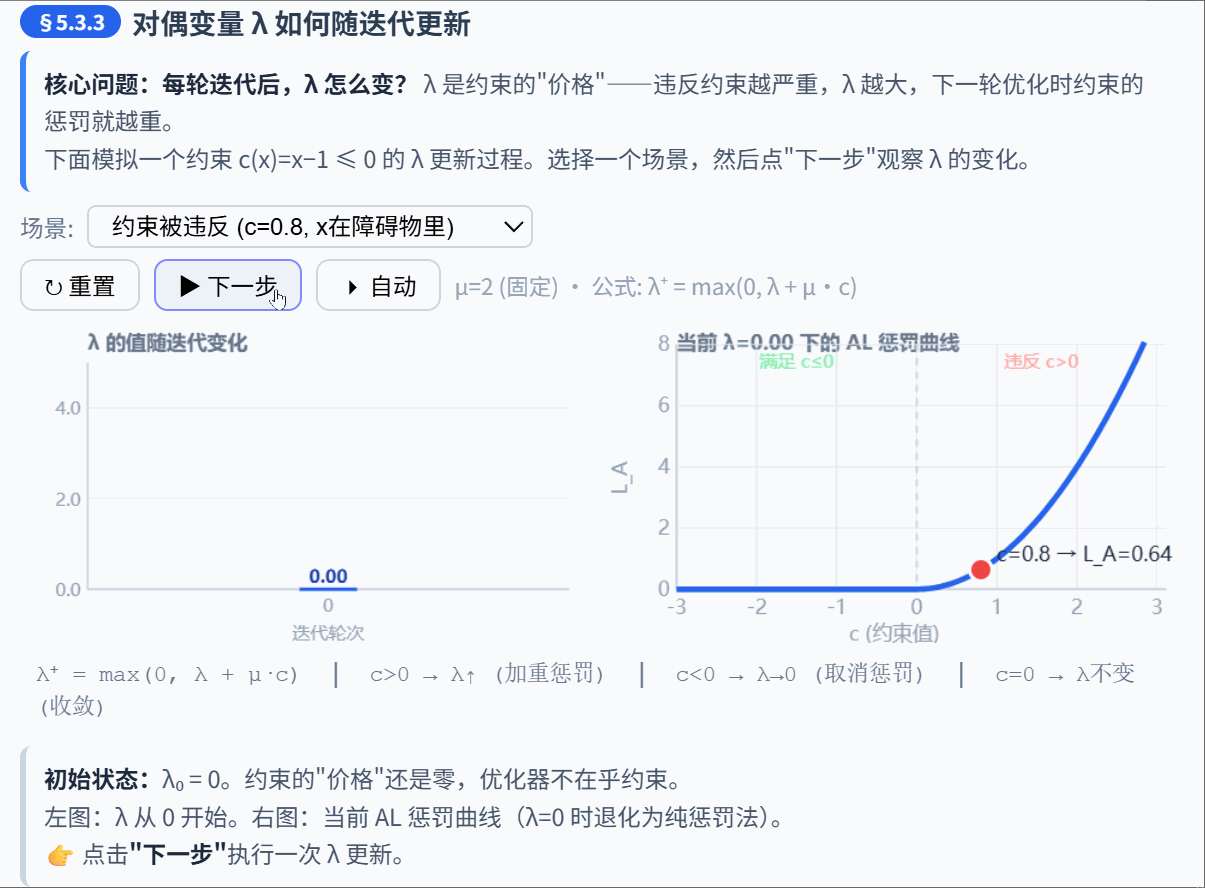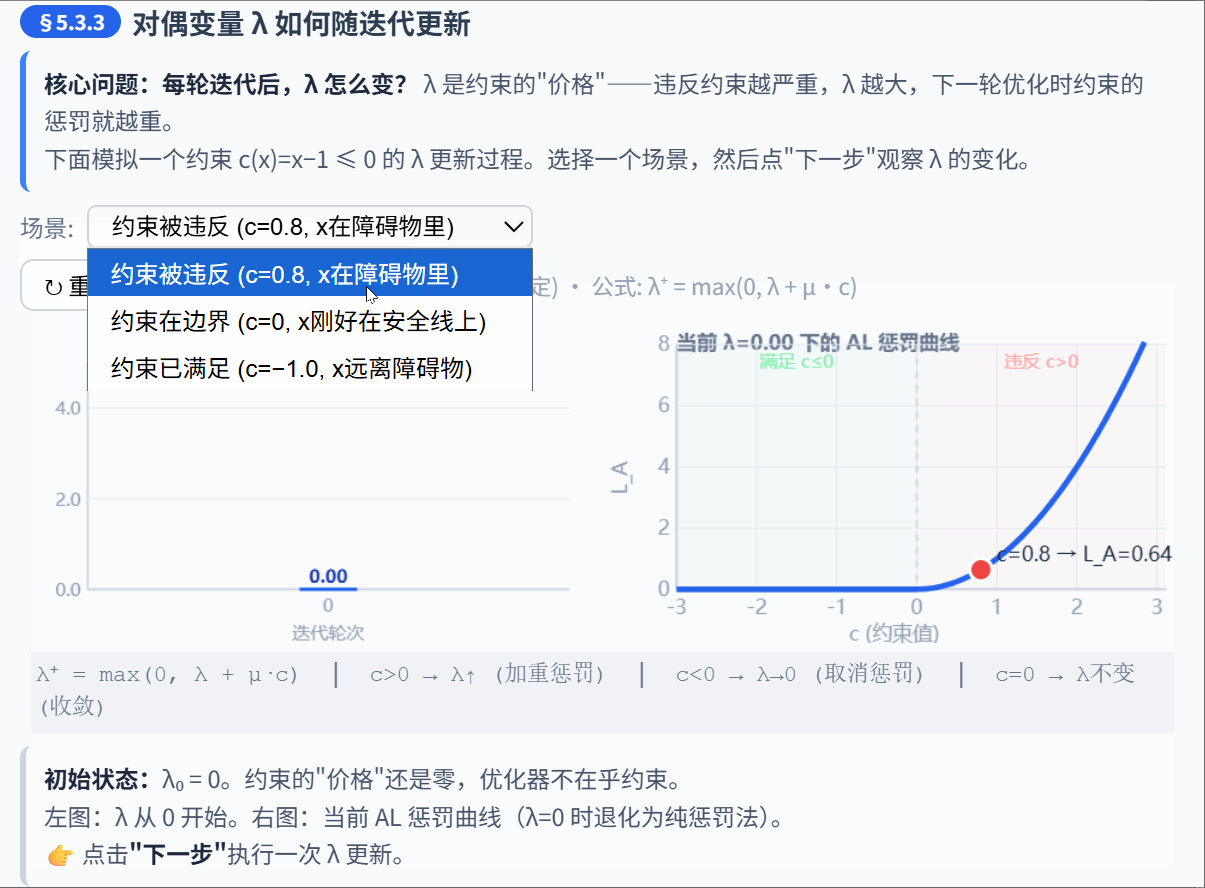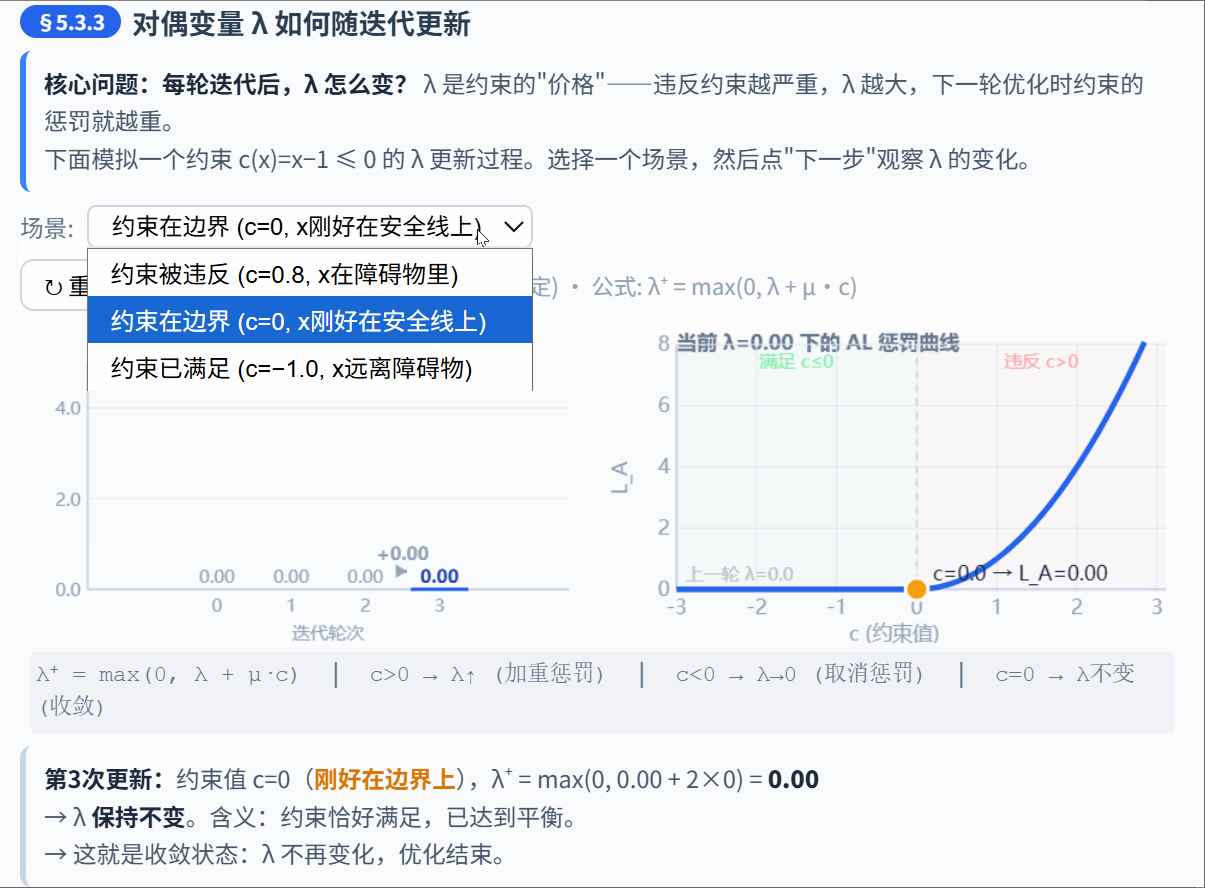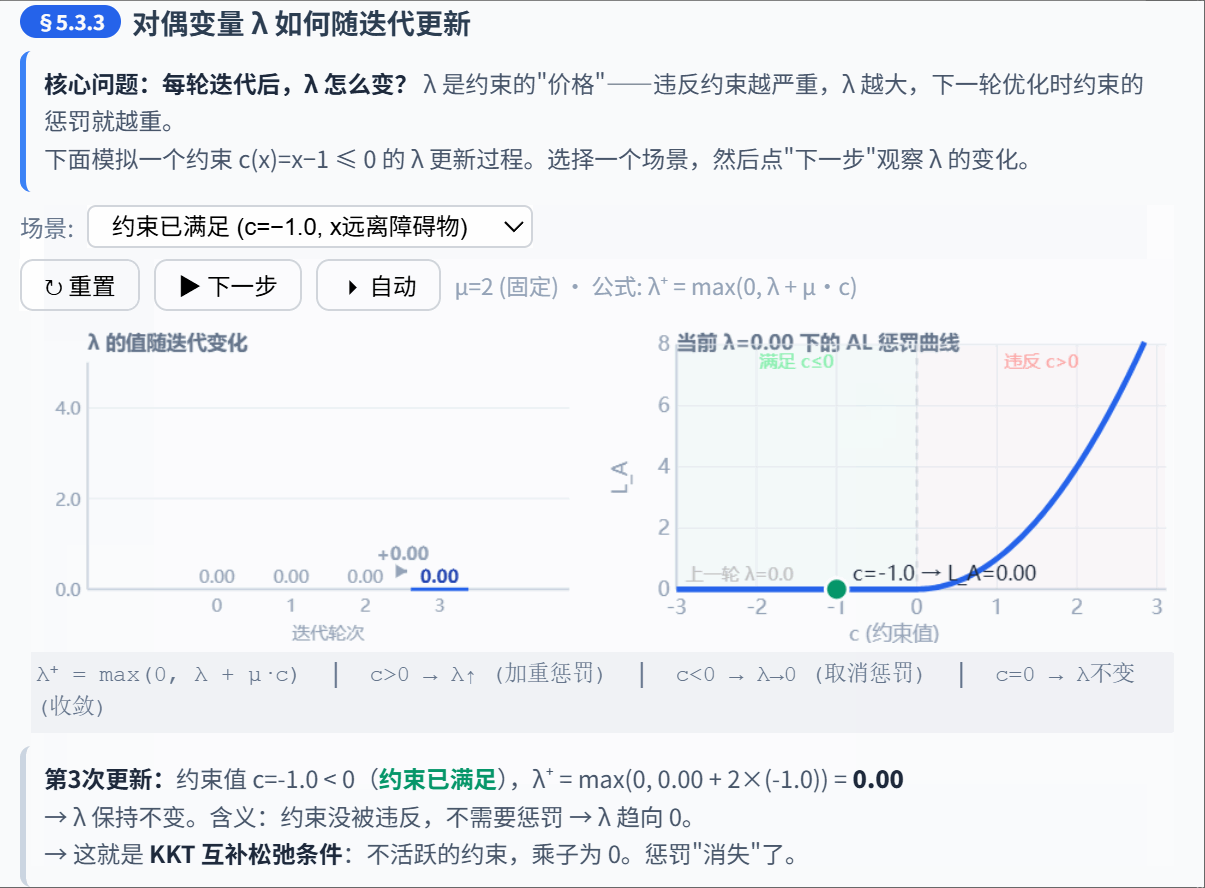
5.3.3 对偶变量更新
在每次外层迭代后,根据当前的约束违反程度更新 :
直觉:
- 如果约束还在被违反(), 增大 → 下次优化时对这个约束的惩罚更重
- 如果约束已经满足(),不等式的 确保 (KKT 互补松弛条件)
- 等式约束没有这个限制, 可以是任意实数
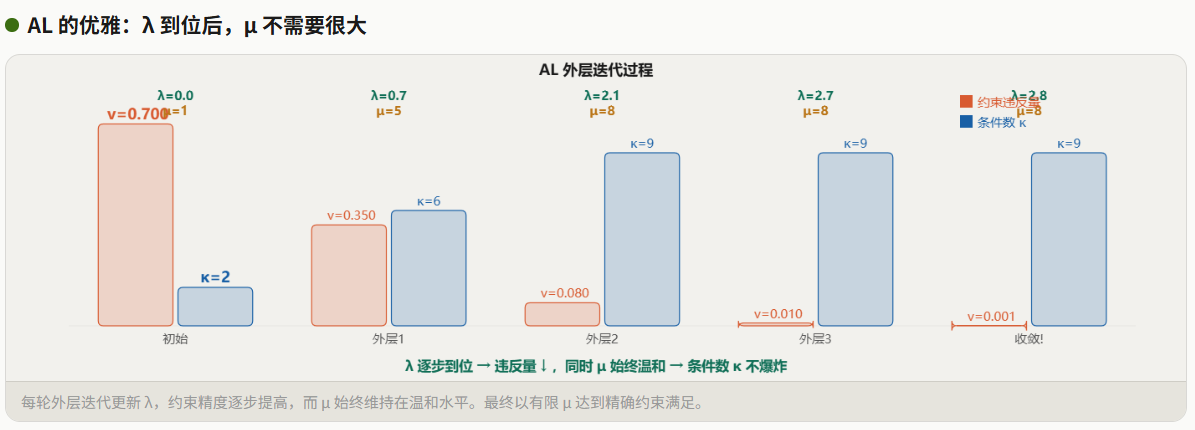
对偶变量更新的意义: 在逐步"学习"每个约束的正确价格。经过足够多轮更新后, 会收敛到最优拉格朗日乘子。此时,即使 不是无穷大,约束也能被精确满足。
5.3.4 惩罚参数更新
如果约束收敛太慢,增大惩罚力度:
是惩罚缩放因子。本项目默认 ,论文典型值 。
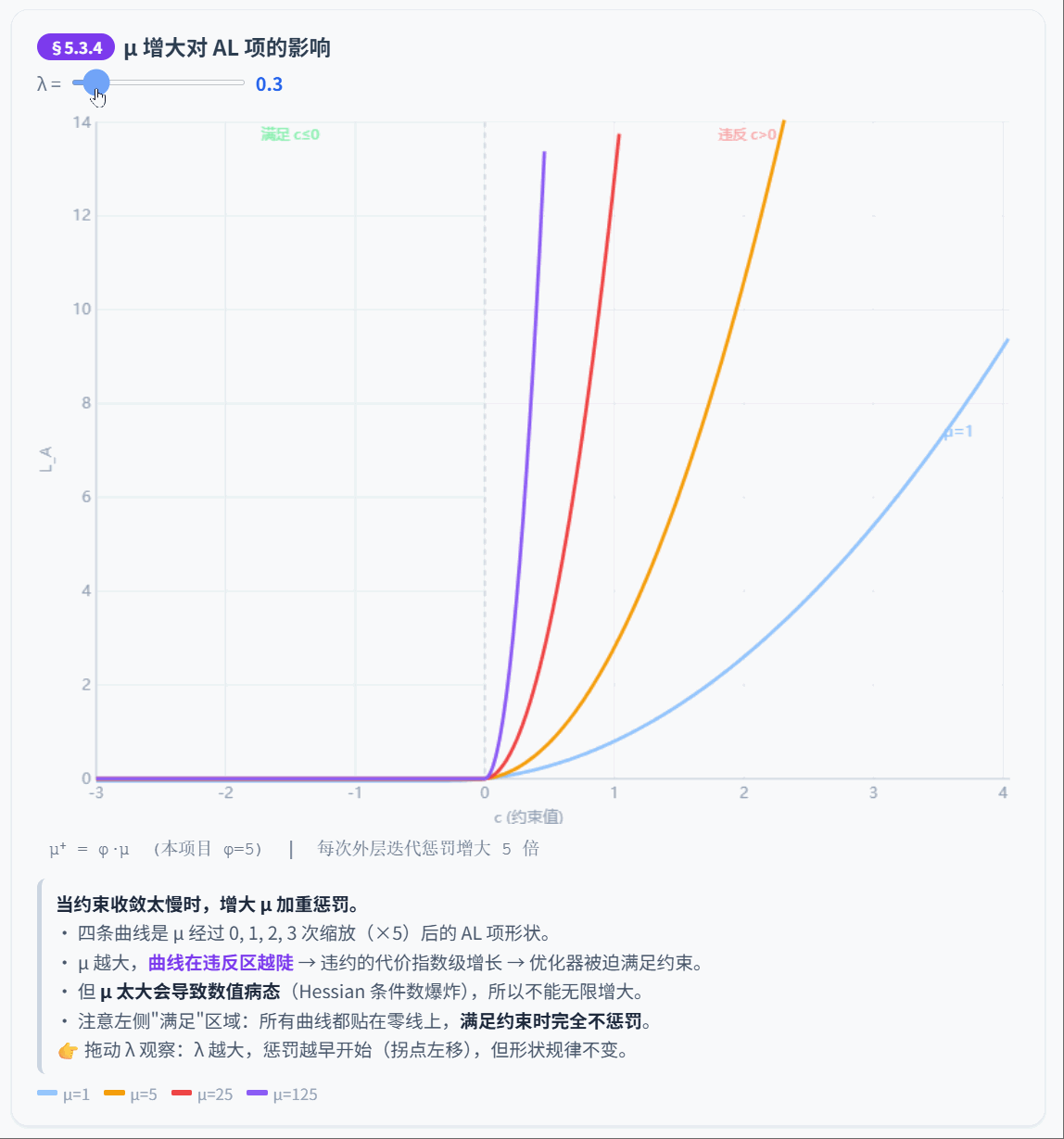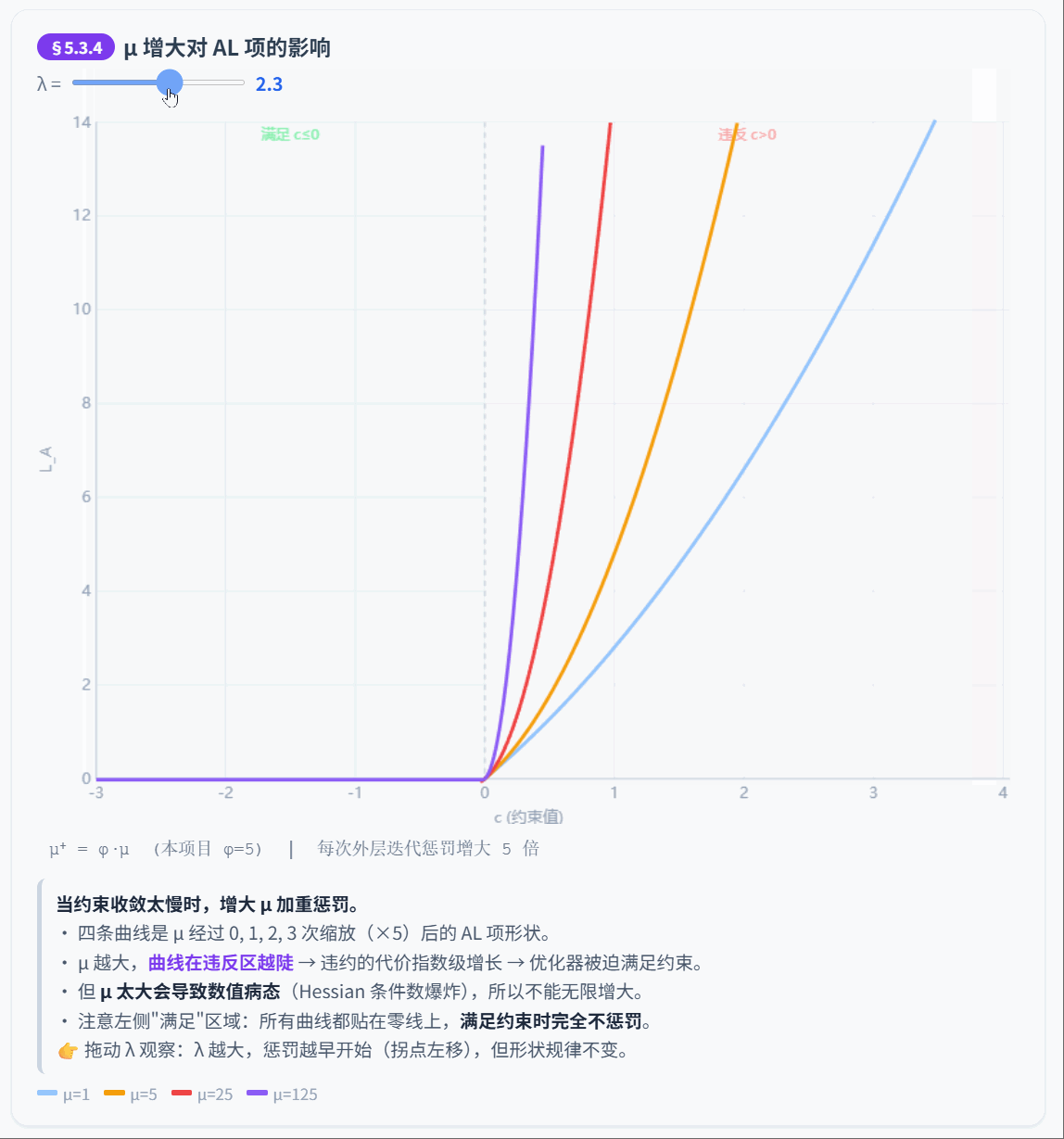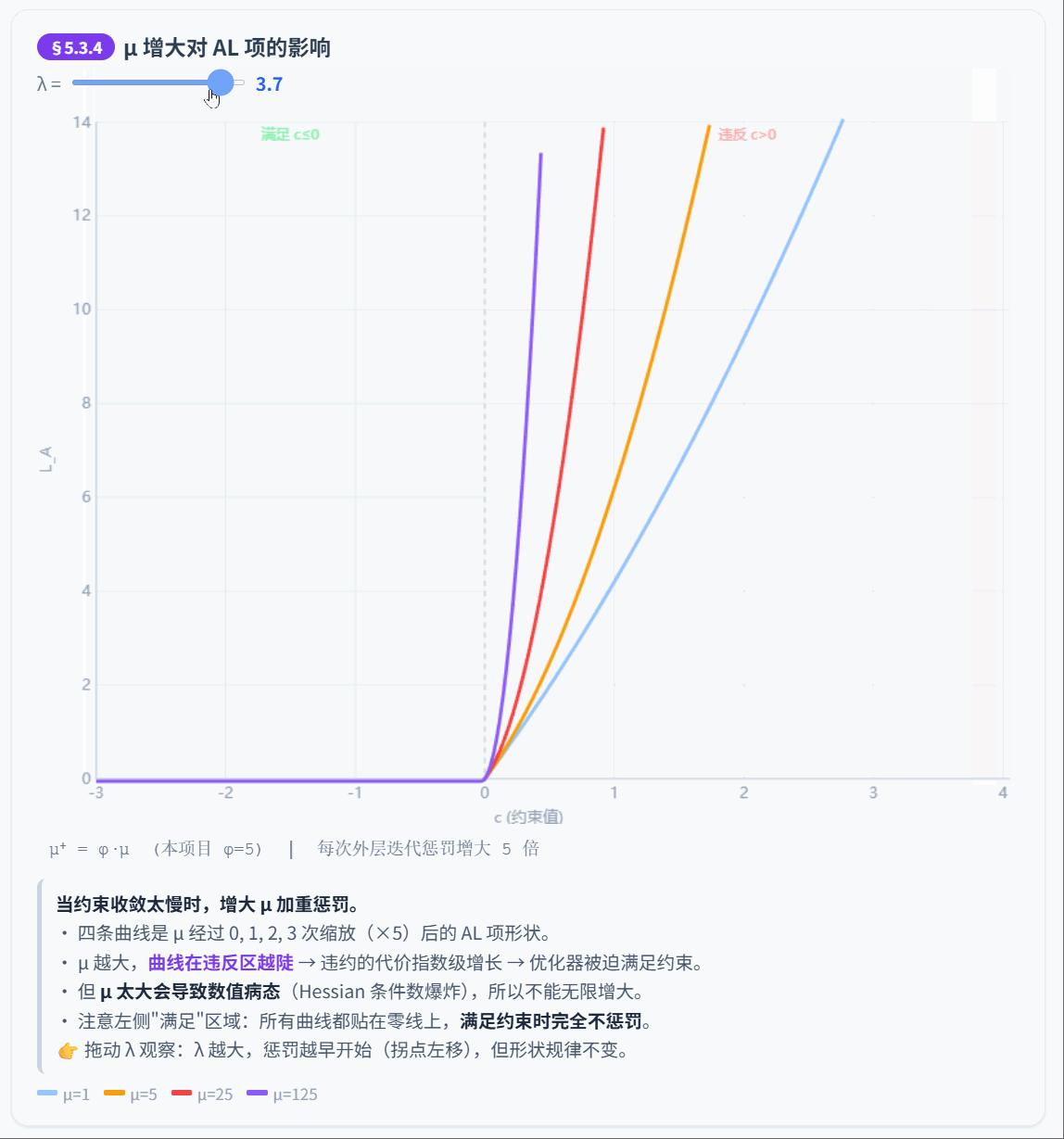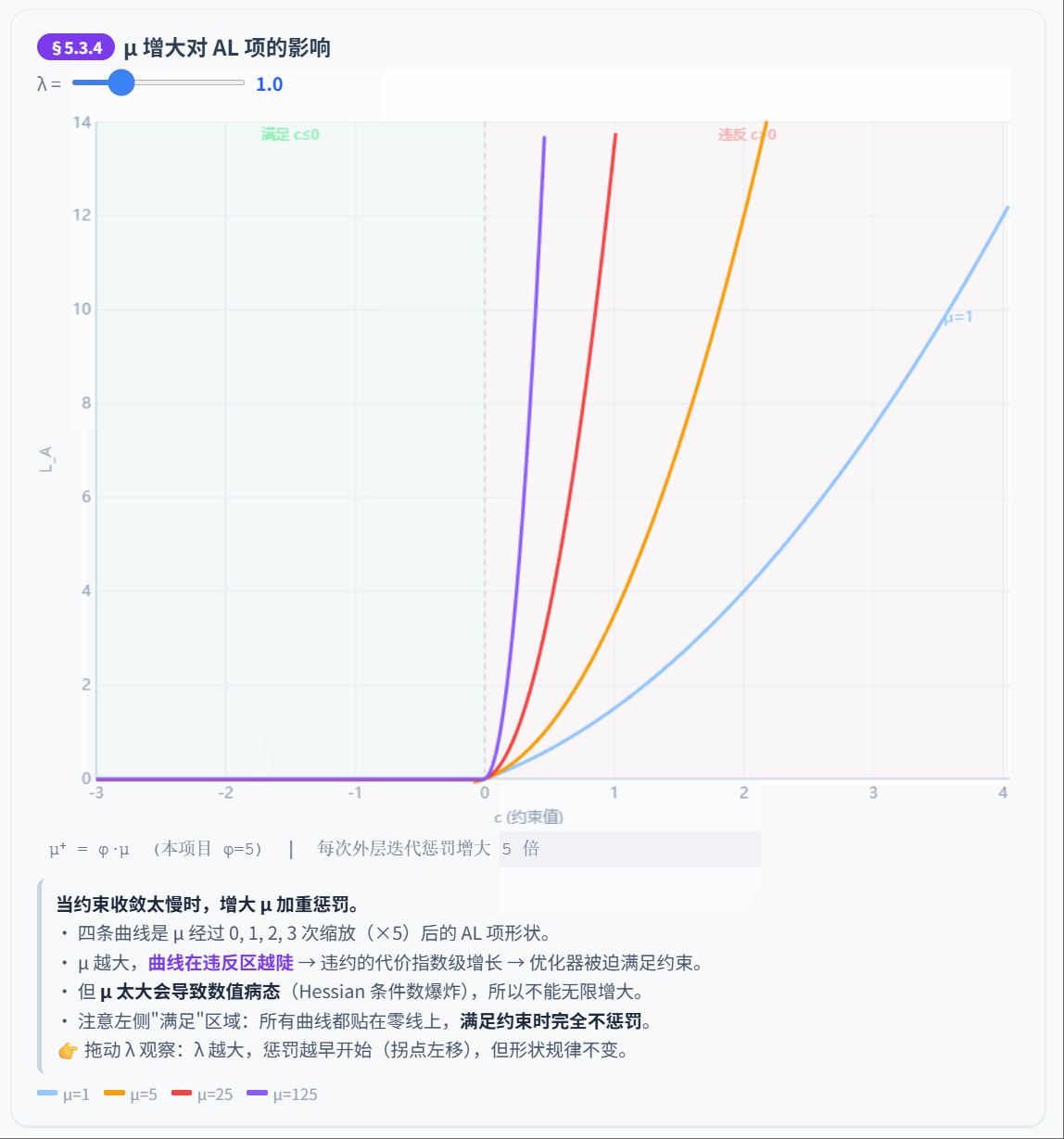
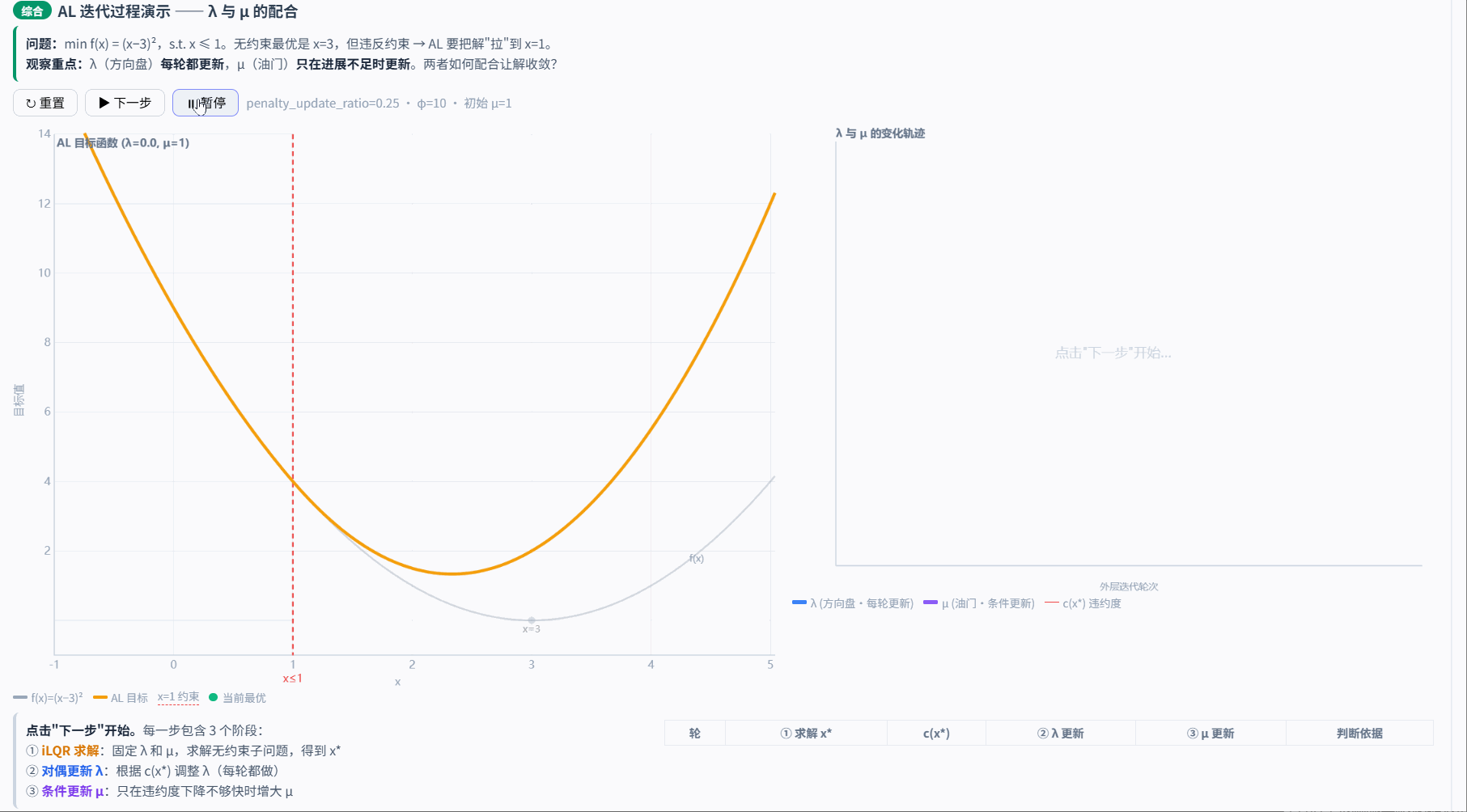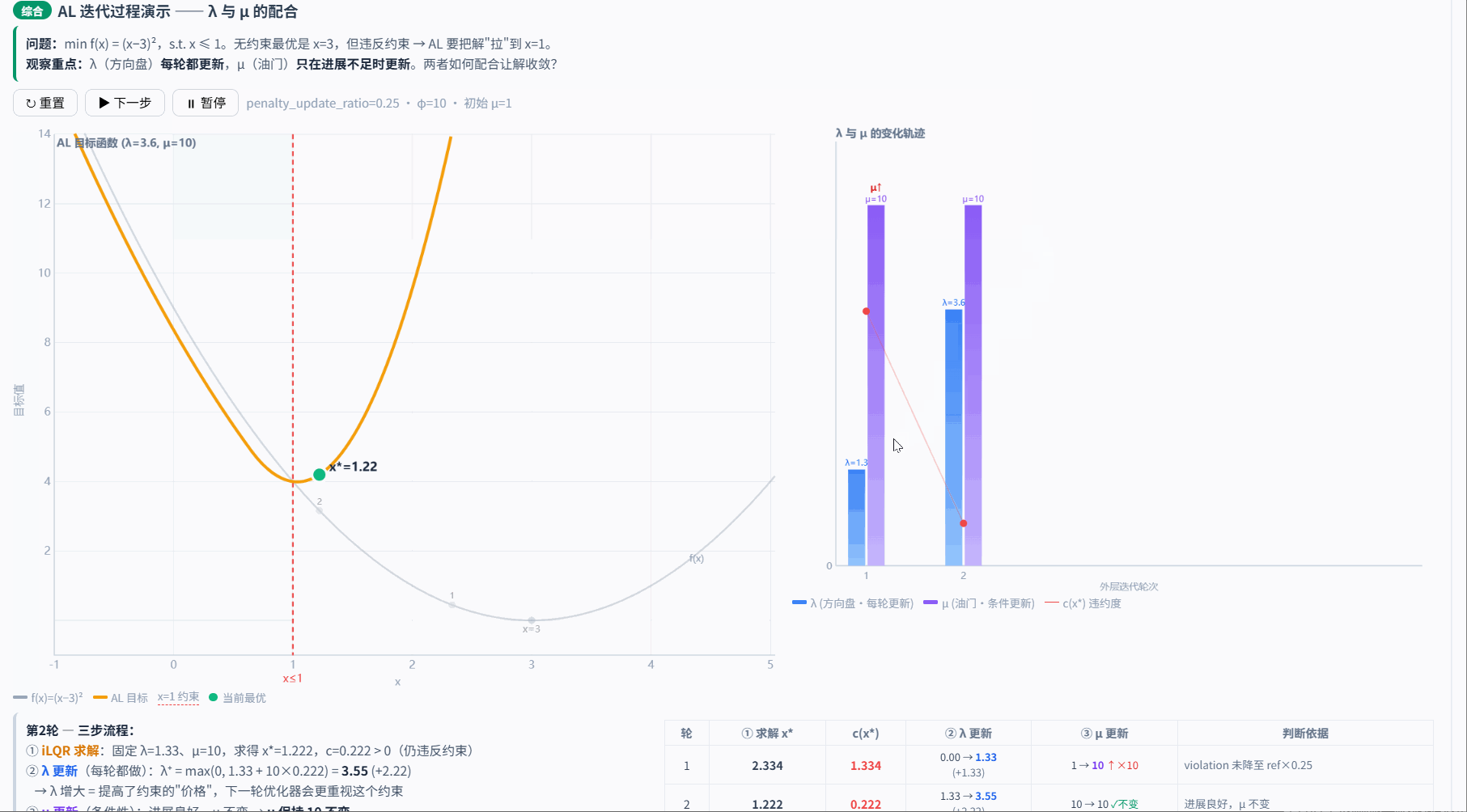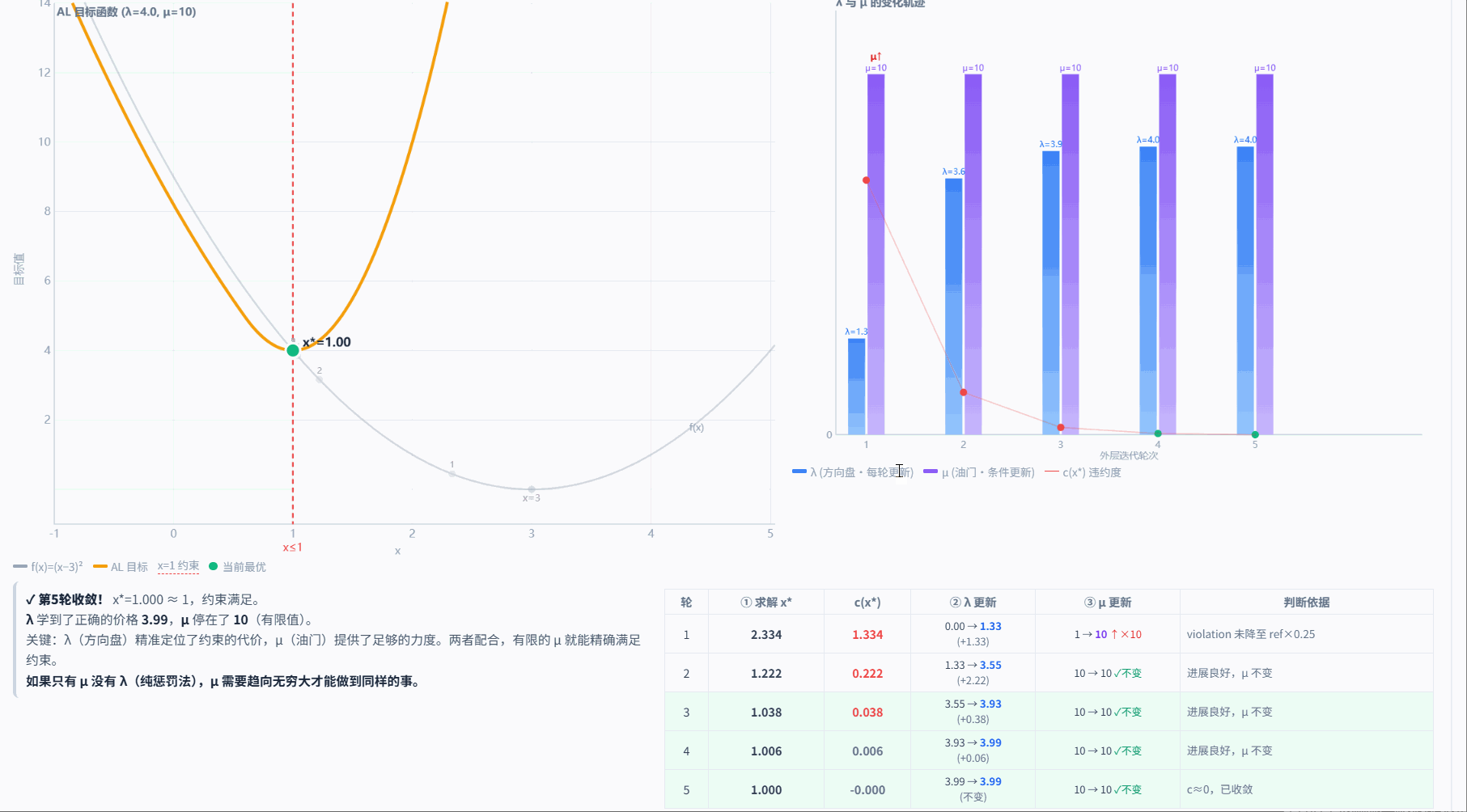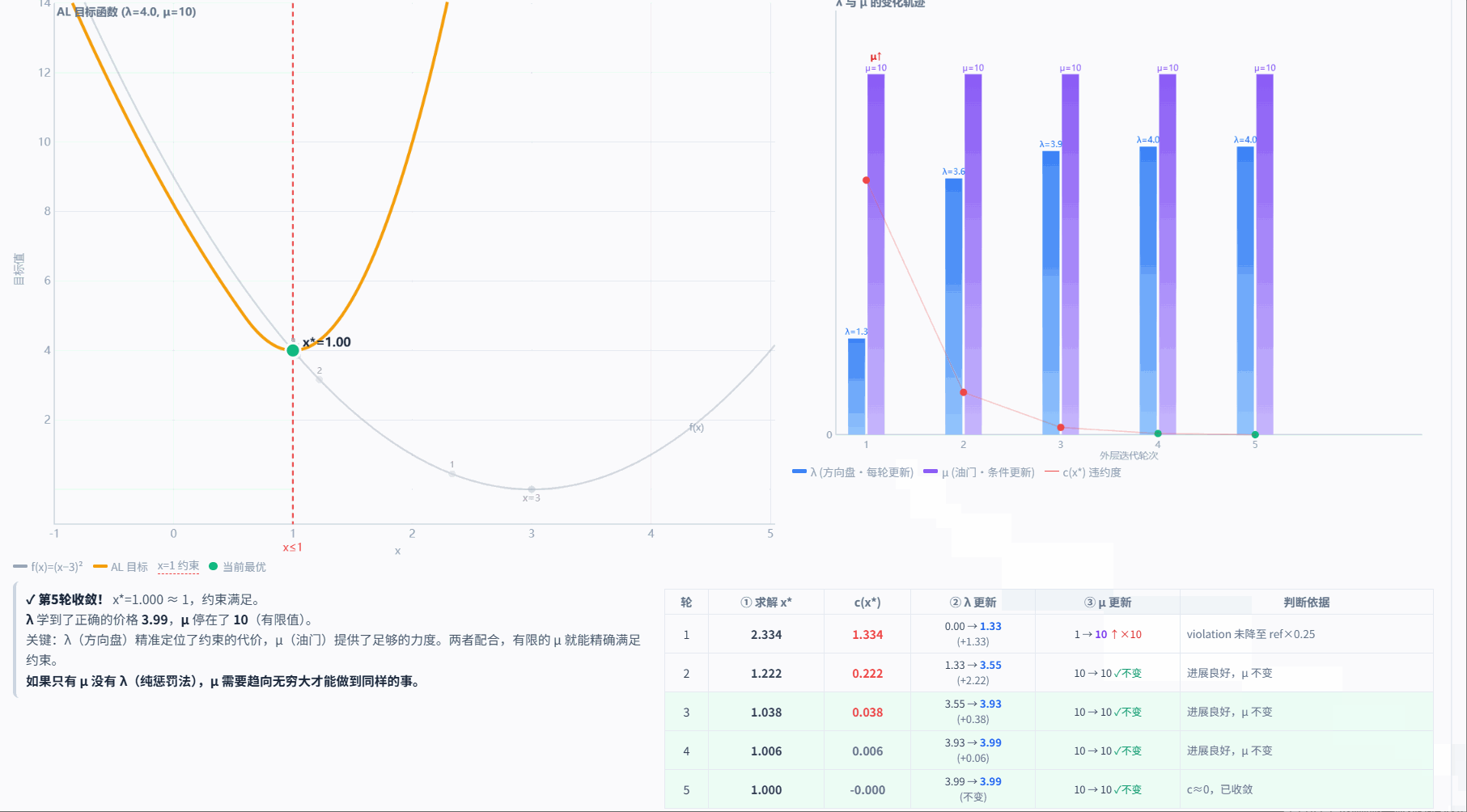
5.3.5 对偶变量和惩罚参数更新示例
两者的分工关系
| λ(对偶变量) | μ(惩罚参数) | |
|---|---|---|
| 角色 | "方向盘" — 指出哪些约束重要 | "油门" — 控制惩罚力度 |
| 更新频率 | 每轮都更新 | 只在进展不足时更新 |
| 更新依赖 | 依赖当前轨迹的约束值 c | 依赖违约度的下降速度 |
| 相互影响 | λ 更新时不看 μ 是否变了 | μ 更新时不看 λ 变成了多少 |
| 但公式耦合 | λ⁺ = max(0, λ + μ·c) ← 用到了 μ | μ 增大后,下一轮 λ 的更新步长也变大 |
关键点在最后一行:虽然更新操作本身是独立的(先更新 λ、再决定是否更新 μ),但通过公式它们是耦合的。
具体来说,λ 的更新公式是 λ⁺ = max(0, λ + μ·c),这里面用到了当前的 μ。所以:
- 如果 μ 小(比如初始的 10),λ 每轮增长 μ·c = 10×c,步子小
- 如果 μ 大(经过几次缩放变成 250),λ 每轮增长 250×c,步子大
用一个生活类比:
想象你在调一个空调的温度:
- λ 是你设定的目标温度:每次感受到"太热了"(c>0),你就把目标调低一点
- μ 是空调的功率:如果调了几次温度还是没效果,你就把空调功率开大
两个旋钮各自独立转动,但它们通过"房间温度"这个共同变量耦合在一起:
- 功率大 → 温度变化快 → 下次调目标时偏差已经小了
- 目标准确 → 即使功率不大也能精确控温(这就是 AL 优于纯惩罚法的地方)
论文 vs 本项目的区别:
论文建议 λ 和 μ 每轮都无条件更新,比较简单。本项目的改进是让 μ 的更新变成有条件的——只在 λ 的更新效果不够好时(违约度下降不够快)才增大 μ,避免 μ 过早爆炸导致数值问题。
示例
5.3.6 符号对照表
| 符号 | 代码变量 | 含义 | 初始值 |
|---|---|---|---|
data.lambda(i) | 第 个约束的拉格朗日乘子 | 0 | |
data.mu(i) | 第 个约束的惩罚参数 | initial_penalty (默认 10) | |
data.penalty_scaling | 惩罚缩放因子 | penalty_scaling (默认 5) | |
values(i) | 第 个约束的取值 | - | |
constraint->OutputDim() | 约束的输出维度 | - |
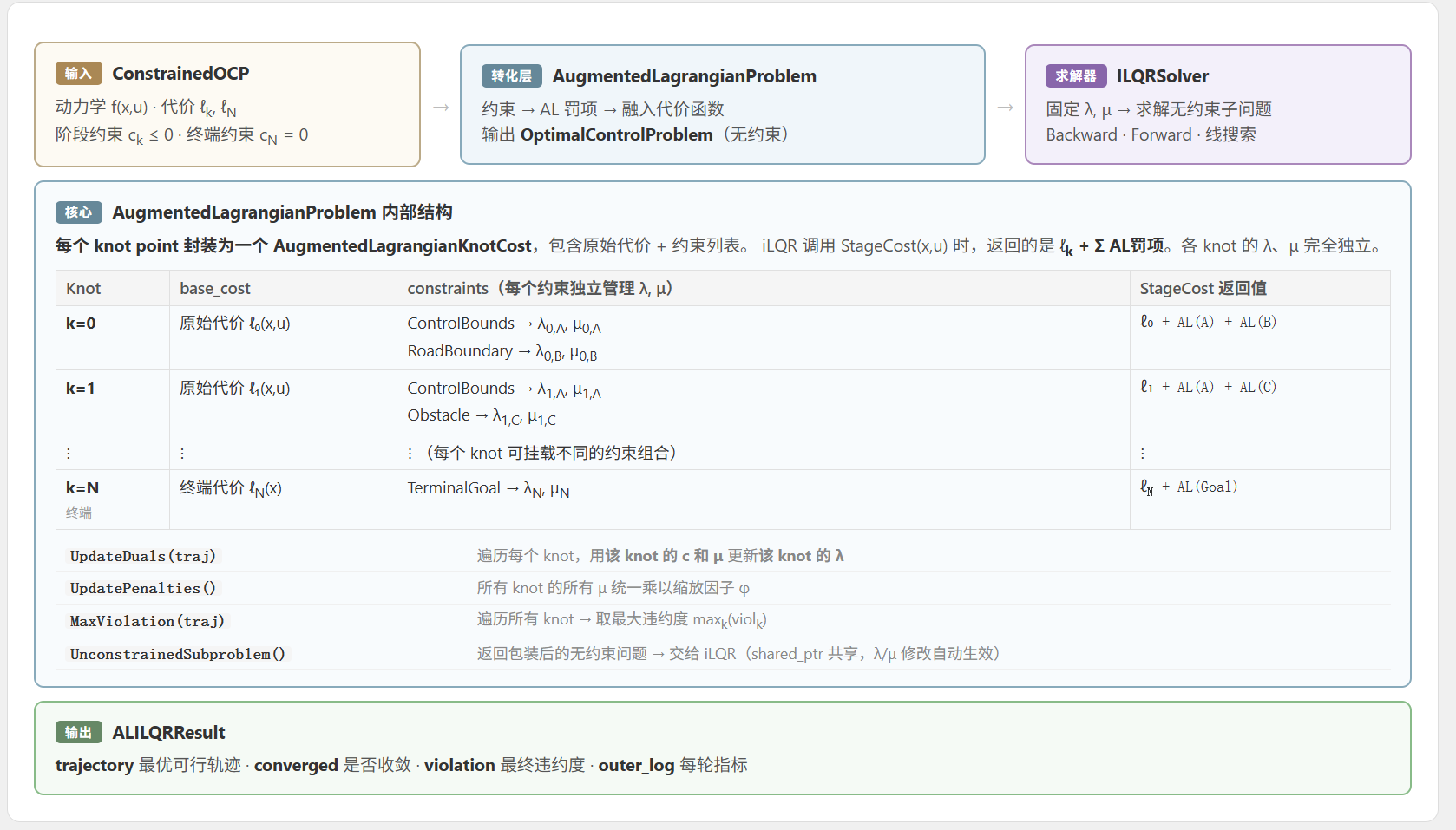
5.4 代码实现:数据结构
5.4.1 每个约束的 AL 数据
每个约束在 AL 框架下需要额外存储 和 :
// include/al/augmented_lagrangian_cost.hpp
struct AugmentedLagrangianConstraintData {
ConstraintPtr constraint; // 指向原始约束(Chapter 4 定义的)
Vector lambda; // 对偶变量 λ (p×1)
Vector mu; // 惩罚参数 μ (p×1), 每个约束分量独立
double penalty_scaling = 10.0; // 缩放因子 φ
};
注意 和 都是向量而不是标量——每个约束分量有自己独立的 和 。例如 ControlBoxConstraint 输出维度 ( 个控制量,每个有上下界),所以有 个独立的 和 。
初始化时,(不知道约束有多重要), 统一设为初始惩罚值:
// src/al/augmented_lagrangian_cost.cpp
AugmentedLagrangianConstraintData MakeConstraintData(
const ConstraintPtr& constraint,
double initial_penalty,
double penalty_scaling) {
return AugmentedLagrangianConstraintData{
constraint,
Vector::Zero(constraint->OutputDim()), // λ = 0
Vector::Constant(constraint->OutputDim(), initial_penalty), // μ = μ₀
penalty_scaling // φ
};
}5.4.2 为什么 λ 初始为 0?
这是一个重要的设计选择。 意味着初始阶段 AL 退化为纯惩罚法:
这样做的好处是:初始 iLQR 求解时,代价函数景观(landscape)与原始问题接近,不会被错误的 引向错误方向。随着迭代进行, 逐渐"学到"正确的值。
5.5 代码实现:AL 代价计算
5.5.1 这一节要解决什么问题?
回顾前面几节,我们已经知道了 AL 的数学公式。但从公式到代码,有一个关键的工程问题需要解答:
iLQR 求解器只认识"代价函数"——它不知道什么是约束。如何让 iLQR 在不修改自身代码的前提下,自动处理约束?
答案就是代价函数包装(cost wrapping)。AugmentedLagrangianKnotCost 类实现了一个"外壳":它对外暴露标准的 CostFunction 接口(StageCost、TerminalCost),但内部偷偷把约束的 AL 罚项加到了代价上。iLQR 以为自己在最小化一个普通代价函数,实际上它在最小化"原始代价 + 约束惩罚",不知不觉中就在满足约束了。
5.5.2 概念模型
下面的示意图展示了 AugmentedLagrangianKnotCost 的内部结构。它持有两样东西:原始代价函数 base_cost_ 和一组约束数据 constraints_(每个约束带着自己的 和 )。当外部调用 StageCost(x, u) 时,它把这些全部加在一起:
┌─────────────────────────────────────────────────────────┐
│ AugmentedLagrangianKnotCost │
│ │
│ ┌──────────────┐ ┌──────────────────────────────┐ │
│ │ base_cost_ │ │ constraints_ │ │
│ │ (原始代价) │ │ [{λ₁,μ₁,约束₁}, │ │
│ │ ℓ(x, u) │ │ {λ₂,μ₂,约束₂}, ...] │ │
│ └──────┬───────┘ └──────────────┬───────────────┘ │
│ │ │ │
│ │ StageCost(x, u) │ │
│ │ ┌──────────────────┐ │ │
│ └──→ │ ℓ(x,u) │ ←─┘ │
│ │ + AL₁(x,u) │ │
│ │ + AL₂(x,u) │ │
│ │ + ... │ │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ 返回总代价值 │
└────────────────────────────────────────────────────────┘
在一个典型的自动驾驶场景中,一个 knot point(轨迹上的一个时间步)可能同时有多个约束:控制量上下界、速度限制、车道边界、障碍物避让……每个约束都会产生自己的 AL 罚项,全部累加到原始代价上。
5.5.3 AL 罚项计算:从公式到代码
这是整个 AL 代价计算的核心——给定一个约束和当前的 ,计算该约束对代价的贡献值(一个标量)。
数学回顾(§5.3 的公式):
对于一个 维的约束 ,AL 罚项是逐分量计算后累加的:
其中每个分量 的计算方式取决于约束类型:
等式约束 :
- :拉格朗日线性项——给约束违反一个线性"价格", 越大,违反代价越高
- :二次惩罚项——无论 正负,只要不为零就产生代价,且二次增长
不等式约束 :
这个公式比等式复杂,关键是 的投影操作:
- 当 (约束被违反或接近边界):产生罚项,推动优化器远离违反区域
- 当 (约束被充分满足): 截断为 0,(常数),不影响优化方向
为什么减去 ? 减去 是为了让约束充分满足时 接近常数(不影响梯度),而不是产生一个随 变化的偏移。
以下代码是上述公式的直接翻译:
// src/al/augmented_lagrangian_cost.cpp
double AugmentedLagrangianKnotCost::ConstraintAugmentedTerm(
const AugmentedLagrangianConstraintData& data,
const Vector& state,
const Vector& control) const {
// Step 1: 计算约束值 c(x, u) → p 维向量
const Vector values = data.constraint->Evaluate(state, control);
double total = 0.0;
// Step 2: 对每个约束分量,按类型计算 AL 项
for (int i = 0; i < values.size(); ++i) {
if (data.constraint->Type() == ConstraintType::kEquality) {
// 等式约束: L_A,i = λᵢ·cᵢ + μᵢ/2 · cᵢ²
total += data.lambda(i) * values(i)
+ 0.5 * data.mu(i) * values(i) * values(i);
} else {
// 不等式约束: L_A,i = [max(0, λᵢ + μᵢ·cᵢ)² - λᵢ²] / (2μᵢ)
const double projected = std::max(0.0, data.lambda(i) + data.mu(i) * values(i));
total += (projected * projected - data.lambda(i) * data.lambda(i))
/ (2.0 * data.mu(i));
}
}
return total;
}代码与公式的逐行对应:
| 代码 | 公式 | 含义 |
|---|---|---|
values(i) | 第 个约束分量的当前值 | |
data.lambda(i) * values(i) | 拉格朗日线性项(等式) | |
0.5 * data.mu(i) * values(i) * values(i) | 二次惩罚项(等式) | |
std::max(0.0, data.lambda(i) + data.mu(i) * values(i)) | 投影操作(不等式) | |
(projected² - lambda²) / (2μ) | 不等式 AL 项 |
具体示例:假设某 knot point 有一个速度约束 ,当前 ,,,:
- (违反)
这个 14.0 的罚项会加到原始代价上,迫使优化器降低速度。
5.5.4 总代价 = 原始代价 + AL 罚项
有了单个约束的 AL 罚项计算,总代价的计算就很直观了:把原始代价和所有约束的 AL 罚项简单相加。
iLQR 求解器调用 StageCost(x, u) 时,拿到的就是这个 ——它完全不知道约束的存在,只看到一个"代价值偏高"的普通函数。
double AugmentedLagrangianKnotCost::StageCost(const Vector& state, const Vector& control) const {
double cost = base_cost_->StageCost(state, control); // 原始代价 ℓ(x, u)
for (const auto& data : constraints_) {
cost += ConstraintAugmentedTerm(data, state, control); // + 每个约束的 AL 项
}
return cost;
}
终端代价同理,只是终端时刻没有控制量输入(轨迹最后一步只有状态,不再施加控制):
double AugmentedLagrangianKnotCost::TerminalCost(const Vector& state) const {
double cost = base_cost_->TerminalCost(state);
for (const auto& data : constraints_) {
cost += TerminalAugmentedTerm(data, state);
}
return cost;
}梯度和 Hessian 怎么办? iLQR 的 backward pass 需要代价函数的梯度和 Hessian(见 Chapter 3)。本项目使用数值微分(有限差分法)来计算 对 的梯度和 Hessian,而不是手动推导 AL 罚项的解析导数。这样做的好处是不需要为每种约束类型单独推导导数公式,新增约束只需实现 Evaluate() 即可。代价是计算量稍大,但对于典型的规划问题规模(几十个 knot point),这是完全可接受的。
5.5.5 对偶变量更新:λ 的学习过程
对偶变量 不是一次算出来的,而是在 AL 外层循环中逐步学习的。每轮外层迭代结束后,内层 iLQR 给出了一条近似最优轨迹,我们沿着这条轨迹在每个 knot point 更新 。
更新公式(§5.3.3 的回顾):
-
等式约束: - 直觉: 表示约束被违反 → 增大 → 下一轮惩罚更重 - 直觉: 同理 → 减小 → 自动纠偏 - 等式约束的 可正可负(因为等式两边对称)
-
不等式约束: - 与等式约束相比多了一个 投影 - 当约束被充分满足()时,,被截断为 0 - 意味着"这个约束目前不活跃,不需要额外惩罚" - 这与 KKT 条件的互补松弛性一致:
为什么 是逐分量更新的? 一个约束函数(如 ControlBoxConstraint)可能输出 维向量,每个分量代表一个独立的约束条件。例如 时可能是:、、、。这 4 个约束的活跃情况可能完全不同(可能只有 的上界被触及),所以各自需要独立的 。
void AugmentedLagrangianKnotCost::UpdateDuals(const Vector& state, const Vector& control) {
for (auto& data : constraints_) {
const Vector values = data.constraint->Evaluate(state, control);
if (data.constraint->Type() == ConstraintType::kEquality) {
// 等式: λ⁺ = λ + μ ⊙ c (⊙ 表示逐元素乘法)
data.lambda += data.mu.cwiseProduct(values);
} else {
// 不等式: λ⁺ = max(0, λ + μ ⊙ c)
data.lambda = (data.lambda + data.mu.cwiseProduct(values)).cwiseMax(0.0);
}
}
}其中 cwiseProduct 是 Eigen 的逐元素乘法(,即每个 乘以对应的 ),cwiseMax(0.0) 是逐元素取 。
5.5.6 惩罚参数更新:μ 的增长
惩罚参数 的更新比 简单——它只是乘以一个固定的缩放因子 (在本项目中默认 ):
void AugmentedLagrangianKnotCost::UpdatePenalties() {
for (auto& data : constraints_) {
data.mu *= data.penalty_scaling; // μ⁺ = φ · μ (逐元素)
}
}
注意:这个函数只做"乘以 "这一步机械操作。何时调用这个函数是由外层的 ALILQRSolver 决定的——只有当约束违反度下降不够快时才会调用(条件性更新,详见 §5.8)。这里体现了之前讨论的 和 的分工:UpdateDuals() 每轮都调用,UpdatePenalties() 有条件地调用。
为什么 也是逐元素的? 与 类似,不同约束分量可能需要不同强度的惩罚。虽然当前实现中所有分量统一缩放(乘以相同的 ),但数据结构上支持独立控制。
5.5.7 最大违约度:收敛的判据
最大违约度(max violation)是 AL 外层循环判断是否收敛的核心指标。它的含义是:在当前轨迹上,所有约束中被违反得最严重的那个,违反了多少?
- 等式约束取绝对值:因为 才算满足,正负都是违反
- 不等式约束取正部分:因为 才算满足,只有 才违反
当 MaxViolation < 容忍阈值(如 )时,认为所有约束基本满足,AL 迭代可以停止。
double AugmentedLagrangianKnotCost::MaxViolation(const Vector& state, const Vector& control) const {
double max_violation = 0.0;
for (const auto& data : constraints_) {
const Vector values = data.constraint->Evaluate(state, control);
max_violation = std::max(max_violation,
MaxViolationForValues(data.constraint->Type(), values));
}
return max_violation;
}
关键理解:这个函数只计算单个 knot point 的最大违约度。在 §5.6 中,AugmentedLagrangianProblem 会遍历整条轨迹的所有 knot point,取全局最大值。
5.6 AugmentedLagrangianProblem:问题转化器
5.6.1 它做了什么?
AugmentedLagrangianProblem 是一个"转换层",将带约束的最优控制问题(ConstrainedOptimalControlProblem)转化为一个无约束的最优控制问题(OptimalControlProblem),后者可以直接交给 iLQR 求解。
┌───────────────────────────────────────────────────────────────────────┐
│ AugmentedLagrangianProblem (转化器) │
│ │
│ 输入: │
│ ┌───────────────────────────────────────┐ │
│ │ ConstrainedOptimalControlProblem │ │
│ │ ├── 动力学: f(x, u) │ │
│ │ ├── 代价: ℓ_k(x, u), ℓ_N(x) │ │
│ │ ├── 阶段约束: c_k(x, u) ≤ 0 │ ← 来自 Chapter 4 │
│ │ └── 终端约束: c_N(x) = 0 │ │
│ └───────────────────────────────────────┘ │
│ │ │
│ AL 包装 │
│ │ │
│ 输出: ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ OptimalControlProblem (无约束!) │ │
│ │ ├── 动力学: f(x, u) ← 不变 │ │
│ │ ├── 阶段代价: ℓ_k + AL_k ← 增广了 │ ← 交给 iLQR │
│ │ └── 终端代价: ℓ_N + AL_N ← 增广了 │ │
│ └───────────────────────────────────────┘ │
│ │
│ 对外 API: │
│ ├── UnconstrainedSubproblem() → 返回无约束子问题,交给 iLQR │
│ ├── UpdateDuals(trajectory) → 沿轨迹更新所有 knot point 的 λ │
│ ├── UpdatePenalties() → 所有 μ 乘以 φ │
│ ├── MaxViolation(trajectory) → 沿轨迹计算最大约束违反 │
│ └── MaxPenalty() → 返回当前最大的 μ 值 │
└───────────────────────────────────────────────────────────────────────┘
5.6.2 构造过程
// src/al/augmented_lagrangian_cost.cpp
AugmentedLagrangianProblem::AugmentedLagrangianProblem(
const ConstrainedOptimalControlProblem& constrained_problem,
double initial_penalty,
double penalty_scaling) {
auto base_problem = constrained_problem.SharedBaseProblem();
// ── 对每个 knot point k,包装该步的代价 ──
std::vector<std::shared_ptr<CostFunction>> stage_costs;
for (int k = 0; k < base_problem->Horizon(); ++k) {
// 收集该步的所有约束,为每个约束创建 {λ, μ, φ} 数据
std::vector<AugmentedLagrangianConstraintData> constraints;
for (const auto& constraint : constrained_problem.StageConstraints(k)) {
constraints.push_back(MakeConstraintData(constraint, initial_penalty, penalty_scaling));
}
// 用 base_cost + AL约束数据 创建包装代价
auto knot_cost = std::make_shared<AugmentedLagrangianKnotCost>(
base_problem->SharedStageCostFunction(k), constraints);
stage_costs_.push_back(knot_cost);
stage_costs.push_back(knot_cost);
}
// ── 同样包装终端代价 ──
std::vector<AugmentedLagrangianConstraintData> terminal_constraints;
for (const auto& constraint : constrained_problem.TerminalConstraints()) {
terminal_constraints.push_back(
MakeConstraintData(constraint, initial_penalty, penalty_scaling));
}
terminal_cost_ = std::make_shared<AugmentedLagrangianKnotCost>(
base_problem->SharedTerminalCostFunction(), terminal_constraints);
// ── 组装无约束子问题(动力学不变,代价被包装) ──
subproblem_ = std::make_shared<OptimalControlProblem>(
base_problem->SharedDynamics(),
std::move(stage_costs),
terminal_cost_,
base_problem->TimeStep());
}
关键理解:stage_costs_ 和 stage_costs 指向同一组 AugmentedLagrangianKnotCost 对象。当 UpdateDuals() 修改了 stage_costs_[k] 中的 ,subproblem_ 中对应的代价函数自动反映变化(shared_ptr 共享所有权)。这就是为什么不需要每次外层迭代重新构造子问题。
5.6.3 全轨迹操作
UpdateDuals 遍历整条轨迹,在每个 knot point 用当前状态/控制更新 :
void AugmentedLagrangianProblem::UpdateDuals(const Trajectory& trajectory) {
for (int k = 0; k < static_cast<int>(stage_costs_.size()); ++k) {
stage_costs_[k]->UpdateDuals(trajectory.State(k), trajectory.Control(k));
}
// 终端只有状态,没有控制量
terminal_cost_->UpdateDuals(trajectory.State(trajectory.Horizon()), EmptyControl());
}
MaxViolation 遍历整条轨迹,找出所有 knot point 中最大的约束违反:
double AugmentedLagrangianProblem::MaxViolation(const Trajectory& trajectory) const {
double max_violation = 0.0;
for (int k = 0; k < static_cast<int>(stage_costs_.size()); ++k) {
max_violation = std::max(max_violation,
stage_costs_[k]->MaxViolation(trajectory.State(k), trajectory.Control(k)));
}
max_violation = std::max(max_violation,
terminal_cost_->MaxViolation(trajectory.State(trajectory.Horizon()), EmptyControl()));
return max_violation;
}
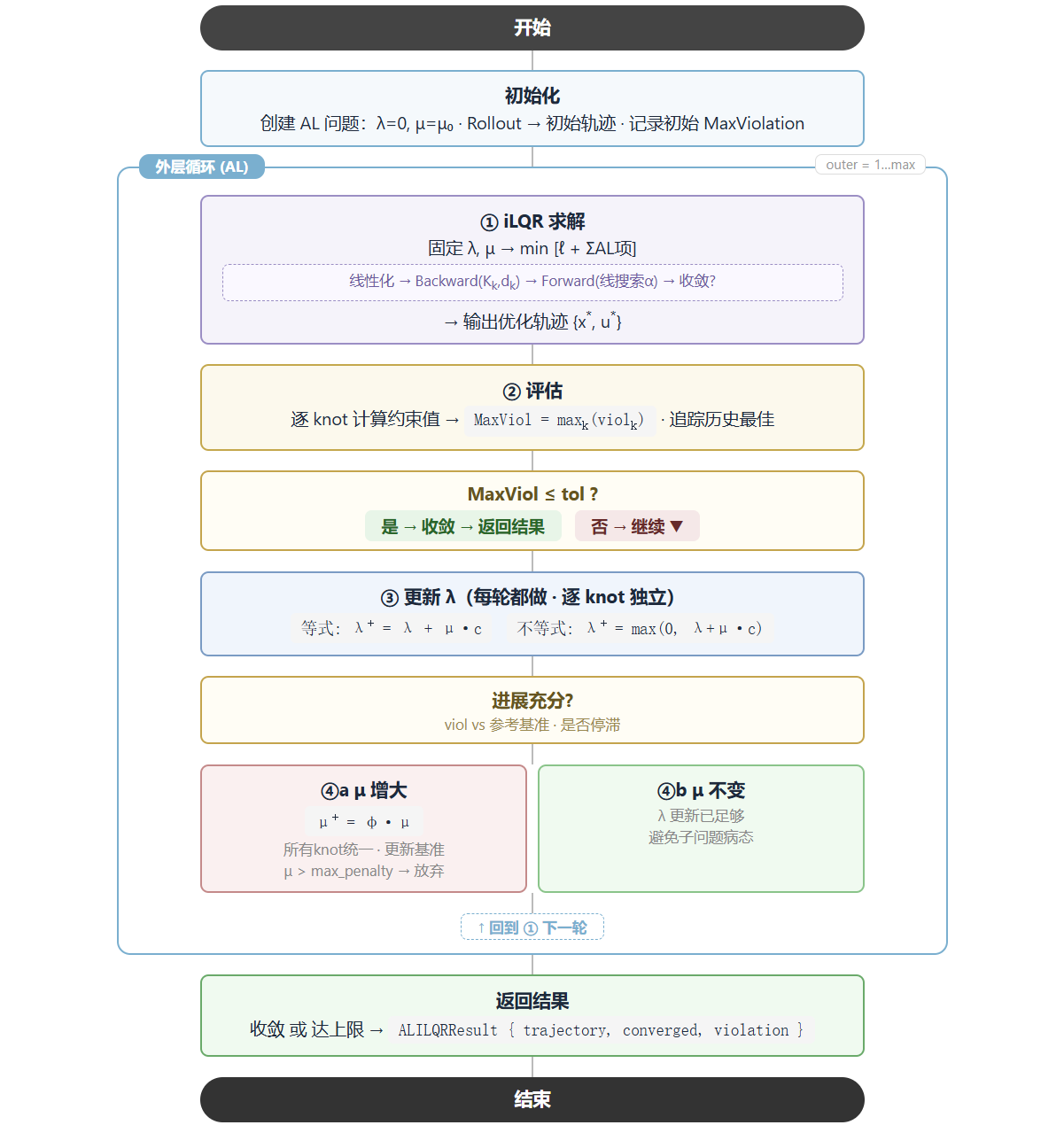
5.7 AL-iLQR 求解主流程
逐行代码解读
// src/al/al_ilqr_solver.cpp
ALILQRResult ALILQRSolver::Solve(
const Vector& initial_state,
const std::vector<Vector>& initial_controls) {
// ═══════ Step 0: 创建 AL 问题 ═══════
// 将 ConstrainedOCP 转化为无约束子问题
// λ = 0, μ = initial_penalty
AugmentedLagrangianProblem al_problem(
problem_, options_.initial_penalty, options_.penalty_scaling);
// 用初始控制序列做一次 rollout,得到初始轨迹
std::vector<Vector> controls = initial_controls;
Trajectory current_trajectory = problem_.BaseProblem().Rollout(initial_state, controls);
// 记录初始违约度(用于后续比较进展)
double current_violation = problem_.MaxViolation(current_trajectory);
double penalty_reference_violation = current_violation; // 上次增大 μ 时的违约度
double previous_outer_violation = current_violation; // 上一轮外层迭代的违约度
double best_violation = current_violation; // 历史最佳
double final_violation = current_violation;
Trajectory best_trajectory = current_trajectory; // 历史最佳轨迹
bool converged = false;
// ═══════ Step 1: 外层循环 ═══════
for (int outer_iter = 0; outer_iter < options_.max_outer_iterations; ++outer_iter) {
// ─── Step 2: 内层 iLQR 求解 ───
// 创建 iLQR 求解器,对当前的无约束子问题求解
// 注意:每轮外层迭代都创建新的 iLQR 求解器(因为 λ, μ 变了,代价函数变了)
ILQRSolver inner_solver(*al_problem.UnconstrainedSubproblem(), options_.inner_options);
current_trajectory = inner_solver.Solve(initial_state, controls);
controls = ExtractControls(current_trajectory);
// ─── Step 3: 评估结果 ───
const double base_cost = problem_.BaseProblem().TotalCost(current_trajectory);
const double augmented_cost =
al_problem.UnconstrainedSubproblem()->TotalCost(current_trajectory);
const double max_violation = problem_.MaxViolation(current_trajectory);
final_violation = max_violation;
// 追踪历史最佳(因为违约度不一定单调下降)
if (max_violation < best_violation) {
best_violation = max_violation;
best_trajectory = current_trajectory;
}
// 记录本轮日志
outer_log_.push_back(ALILQROuterIterationLog{
outer_iter + 1,
static_cast<int>(inner_solver.AlphaHistory().size()),
base_cost, augmented_cost,
max_violation, best_violation,
al_problem.MaxPenalty(),
false, // penalty_updated, 稍后可能改为 true
});
// ─── Step 4: 收敛检查 ───
if (max_violation <= options_.constraint_tolerance) {
converged = true;
break; // 约束满足, 成功!
}
// ─── Step 5: 更新对偶变量 λ ───
al_problem.UpdateDuals(current_trajectory);
// ─── Step 6: 条件性惩罚更新 ───
const double stagnation_ratio = std::max(options_.penalty_update_ratio, 0.95);
// 判据 1: 与上次增大 μ 时相比,进展不足?
const bool insufficient_progress_since_penalty =
max_violation > penalty_reference_violation * options_.penalty_update_ratio;
// 判据 2: 与上一轮外层迭代相比,几乎停滞?
const bool insufficient_progress_since_last_outer =
outer_iter > 0 &&
max_violation > previous_outer_violation * stagnation_ratio;
if (insufficient_progress_since_penalty || insufficient_progress_since_last_outer) {
al_problem.UpdatePenalties(); // μ *= φ
outer_log_.back().penalty_updated = true;
penalty_reference_violation = max_violation;
if (al_problem.MaxPenalty() > options_.max_penalty) {
break; // μ 太大, 放弃
}
}
previous_outer_violation = max_violation;
}
// ═══════ Step 7: 返回结果 ═══════
const bool use_best_trajectory =
options_.return_best_trajectory && best_violation < final_violation;
const Trajectory& returned_trajectory =
use_best_trajectory ? best_trajectory : current_trajectory;
const double returned_violation =
use_best_trajectory ? best_violation : final_violation;
return ALILQRResult{returned_trajectory, converged, final_violation,
returned_violation, outer_log_};
}AL-iLQR 配置参数
// include/al/al_ilqr_solver.hpp
struct ALILQROptions {
ILQROptions inner_options; // 内层 iLQR 配置 (参见 Chapter 3)
int max_outer_iterations = 10; // 外层最大迭代次数
double constraint_tolerance = 1e-3; // 约束收敛容差: violation < 此值即认为收敛
double initial_penalty = 10.0; // μ 初始值
double penalty_scaling = 5.0; // φ: 惩罚缩放因子
double penalty_update_ratio = 0.25; // 进展判断阈值
double max_penalty = 1e8; // μ 上限, 超过则放弃
bool return_best_trajectory = true; // 是否返回历史最佳轨迹
};
每个参数的详细含义:
| 参数 | 含义 | 设太大 | 设太小 |
|---|---|---|---|
max_outer_iterations | 外层最多跑几轮 | 浪费时间 | 可能未收敛就停了 |
constraint_tolerance | 多小的违约算"满足" | 约束不够精确 | 可能永远达不到 |
initial_penalty | 的起始值 | 初始子问题就很病态 | 约束初始被忽略,需要更多轮 |
penalty_scaling | :每次乘多少 | 爆炸太快 | 收敛太慢 |
penalty_update_ratio | 判断"进展不足"的阈值 | 太容易增大 | 太不容易增大 |
max_penalty | 允许的上限 | 数值可能爆炸 | 可能放弃得太早 |
论文建议(Table II):
initial_penalty的影响最大("Very High"重要性),典型值从 到 不等,取决于问题规模。penalty_scaling通常取 。
5.8 问题
5.8.1 本项目的实现路径:数值差分 vs 论文的解析展开
这是理解本项目与论文差异的关键一节。
论文怎么做
论文(§III-A,公式 41-45)显式地将 AL 项的梯度和 Hessian 展开:
其中 是约束的 Jacobian,需要对每种约束手动推导。
本项目怎么做
本项目把 AL 罚项"藏"在 StageCost() 的返回值里:
StageCost(x, u) = 原始代价 ℓ(x, u) + AL罚项(x, u)
然后 iLQR 的 UpdateExpansions() 对整个 StageCost() 做数值中心差分,得到梯度和 Hessian。约束的 Jacobian 不需要单独计算——它们的效果已经隐含在数值差分中。
论文做法: 本项目做法:
需要手动推导: 只需要:
├── ℓ_x, ℓ_u (代价梯度) ├── StageCost(x, u)
├── ℓ_xx, ℓ_uu (代价 Hessian) │ = base_cost + AL项
├── c_x, c_u (约束 Jacobian) │
├── c_xx, c_uu (约束 Hessian, DDP) └── iLQR 对整体做数值差分
└── 手动组合为 Q_xx, Q_x, ... → 自动得到所有需要的梯度/Hessian
↓ ↓
精确、高效 简洁、通用
但每种约束都要推公式 但计算量更大(多次函数求值)
两种方式数学等价
无论是"先展开再求导"还是"先合并再求导",最终得到的 是一样的。区别纯粹在工程实现上:
| 对比项 | 论文解析展开 | 本项目数值差分 |
|---|---|---|
| 新增约束的工作量 | 需要推导 | 只需实现 Evaluate() |
| 计算效率 | 高(一次矩阵运算) | 低(每个差分方向调用一次约束函数) |
| 精度 | 解析精确 | 受差分步长影响(中心差分误差 ) |
| 代码复杂度 | 高(需维护解析公式) | 低(通用差分框架) |
本项目选择数值差分是一个工程权衡:牺牲一些计算效率,换取极大的开发便利性。
5.8.2 惩罚更新策略详解
论文标准做法
论文(§III-D,公式 58)建议每次外层迭代无条件增大 :
论文作者在第六节也明确表示:"we have found that the most naive approach, that is updating them every outer loop iteration, is by far the most reliable approach."
本项目的改进:条件性更新
本项目采用更保守的策略——只在进展不足时才增大 ,避免 增长过快导致子问题病态。
这是一个工程启发式(heuristic),不是论文的标准公式。
本项目的 μ 更新决策流程:
计算 max_violation
│
┌─────────────┴──────────────┐
│ │
判据 1: 判据 2:
violation > violation >
penalty_ref × 0.25 ? prev_violation × 0.95 ?
│ │
(与上次增大μ时比, (与上一轮比,
减少了 75% 以上?) 减少了 5% 以上?)
│ │
└─────────┬──────────────────┘
│
任一判据为 YES
│
┌────┴────┐
│ │
是: μ *= φ 否: μ 不变
│ │
▼ │
更新 penalty_ref │
│ │
μ > max_penalty?│
├─YES→ 终止 │
└─NO──┬────────┘
│
▼
继续下一轮
判据 1:violation > penalty_reference_violation * 0.25
这个 penalty_reference_violation 是上次增大 时的违约度。如果当前违约度不到上次的 25%(即减少了 75% 以上),说明进展很好,不需要增大 。
判据 2:violation > previous_outer_violation * 0.95
这是停滞检测。如果相比上一轮只减少了不到 5%,说明当前 下的优化已经"到头了",需要加大力度。
注意 stagnation_ratio 的计算:
const double stagnation_ratio = std::max(options_.penalty_update_ratio, 0.95);当 penalty_update_ratio = 0.25 时,stagnation_ratio = 0.95,这意味着判据 2 的阈值固定为 95%。
为什么不是每次都增大 μ?
论文说每次都增大最可靠,但那是对一般问题而言。在自动驾驶场景中:
- 问题规模较大(多个障碍物 × 多圆近似 × 多 knot point),约束数量多
- 增长过快会让 iLQR 的 矩阵条件数恶化
- 条件性更新可以在约束改善充分时"保持"当前 ,减少数值问题
5.8.3 最佳轨迹追踪
为什么需要追踪历史最佳?
AL-iLQR 的违约度不一定单调下降。当 增大时,代价函数的景观(landscape)发生变化,iLQR 可能找到一个"代价更低但违约度稍高"的新解:
外层迭代: 1 2 3 4 5
violation: 0.5 0.1 0.3 0.05 0.001
↑
μ 增大后违约度暂时反弹!
best_violation:
0.5 0.1 0.1 0.05 0.001
↑
保持第 2 次的最佳值
代码实现
// 每轮外层迭代中
if (max_violation < best_violation) {
best_violation = max_violation;
best_trajectory = current_trajectory;
}
// 最终返回时
const bool use_best_trajectory =
options_.return_best_trajectory && best_violation < final_violation;return_best_trajectory = true(默认)时,如果最后一轮的轨迹不是最好的,返回历史最佳。
5.8.4 求解日志
每次外层迭代记录详细信息,便于调试和分析:
struct ALILQROuterIterationLog {
int outer_iteration = 0; // 第几次外层迭代 (1-based)
int inner_iterations = 0; // 内层 iLQR 用了多少步
double base_cost = 0.0; // 不含 AL 项的原始代价
double augmented_cost = 0.0; // 含 AL 项的总代价
double max_violation = 0.0; // 当前最大违约度
double best_violation_so_far = 0.0; // 历史最佳违约度
double max_penalty = 0.0; // 当前最大 μ 值
bool penalty_updated = false; // 本轮是否更新了惩罚
};
返回值也包含完整的求解信息:
struct ALILQRResult {
Trajectory trajectory; // 最终轨迹
bool converged = false; // 是否收敛
double final_violation = 0.0; // 最后一轮的违约度
double best_violation = 0.0; // 历史最佳违约度
std::vector<ALILQROuterIterationLog> outer_logs; // 所有外层迭代的日志
};
5.8.5 为什么 AL 能收敛?
从直觉到理论,分四个层次理解:
层次 1:直觉
- 初始阶段: 较小 → 约束惩罚弱,iLQR 主要优化原始代价
- 对偶更新阶段: 逐渐"学会"约束的重要性 - 被严重违反的约束 → 增长快 → 下轮对该约束惩罚加重 - 已满足的不等式约束 → 截断 → 不增长
- 惩罚增大阶段: 增大让违约"更昂贵",迫使 iLQR 更积极地满足约束
- 收敛:当 收敛到真实的最优乘子时, 不需要趋于无穷大(这是 AL 优于纯惩罚法的关键!)
层次 2:KKT 条件
AL 的收敛本质上是在逼近 KKT(Karush-Kuhn-Tucker)最优性条件:
AL 的对偶更新公式 正是在迭代逼近满足这些条件的 。
层次 3:与纯惩罚法的关键区别
纯惩罚法的最优性条件是 ,只有当 且 时才满足 KKT。而 AL 的最优性条件是 ,当 时,即使 有限, 也能精确为零。
5.9 本章小结
下一步
至此,AL-iLQR 求解器已经完整。但我们还没有看到它如何应用于真实的自动驾驶场景——如何定义车辆动力学、如何组装约束、如何可视化结果。这些将在后续章节中展开。
评论
加入讨论
登录或注册后即可发表评论,与其他学习者交流
0 条评论
加载评论中...