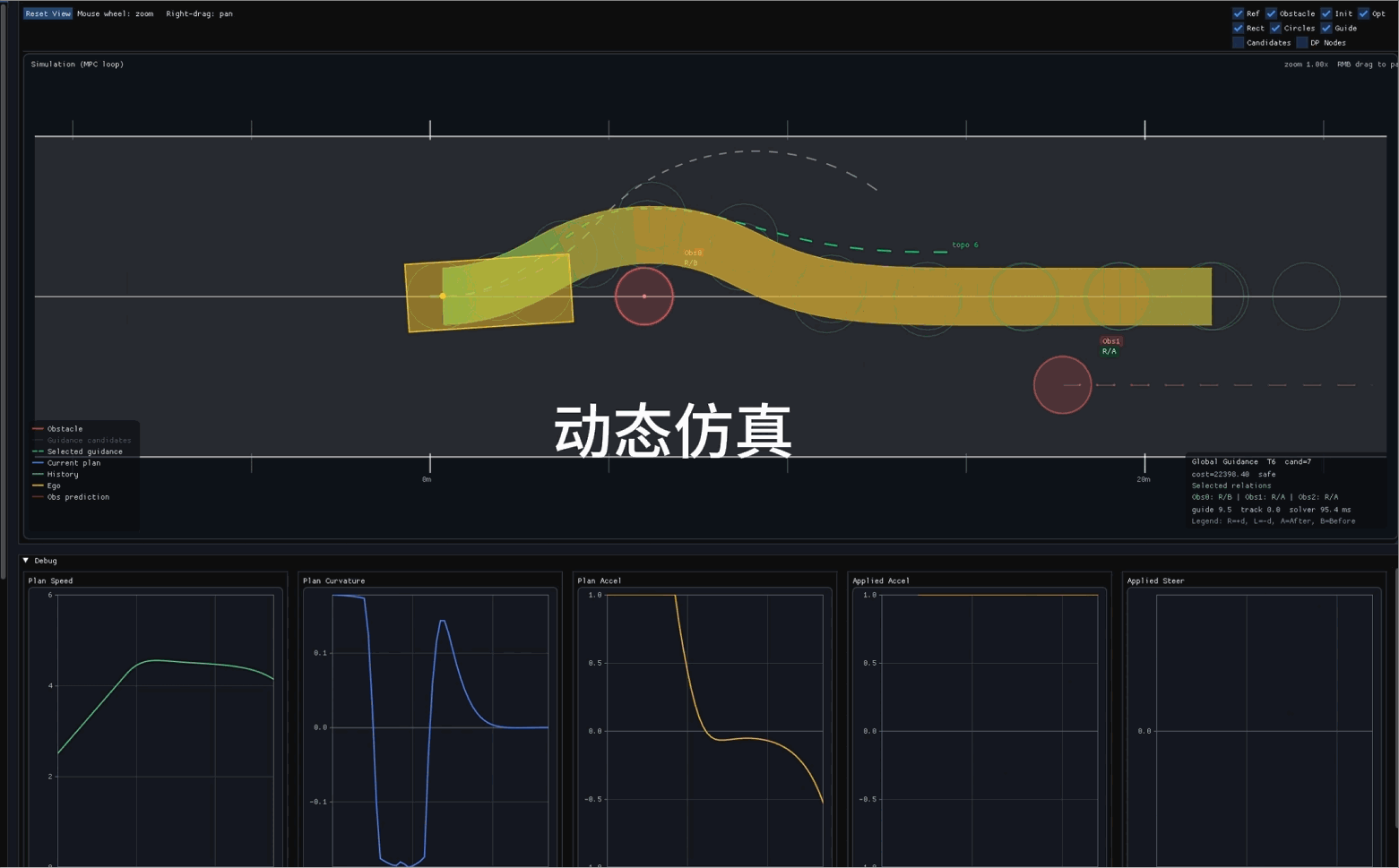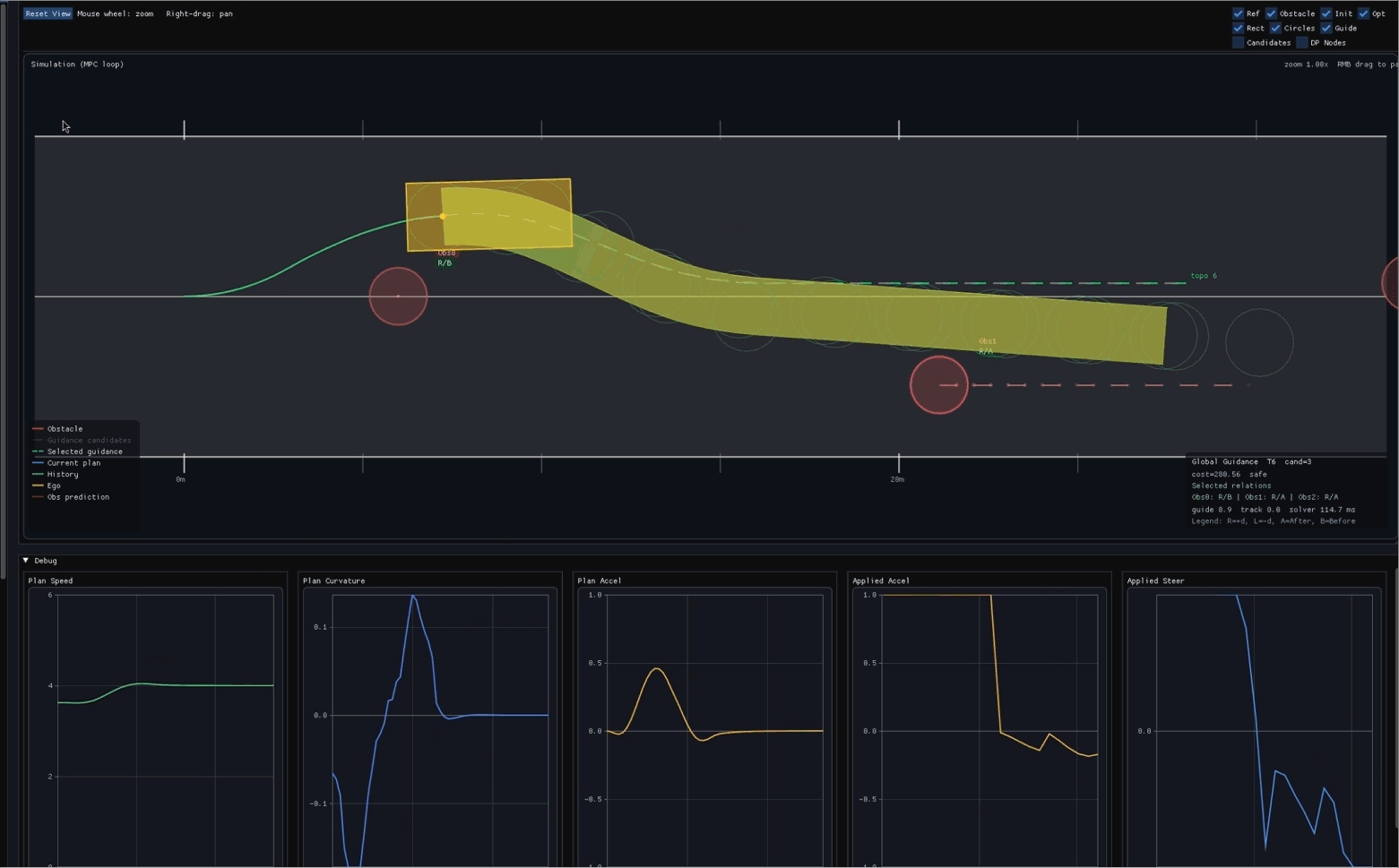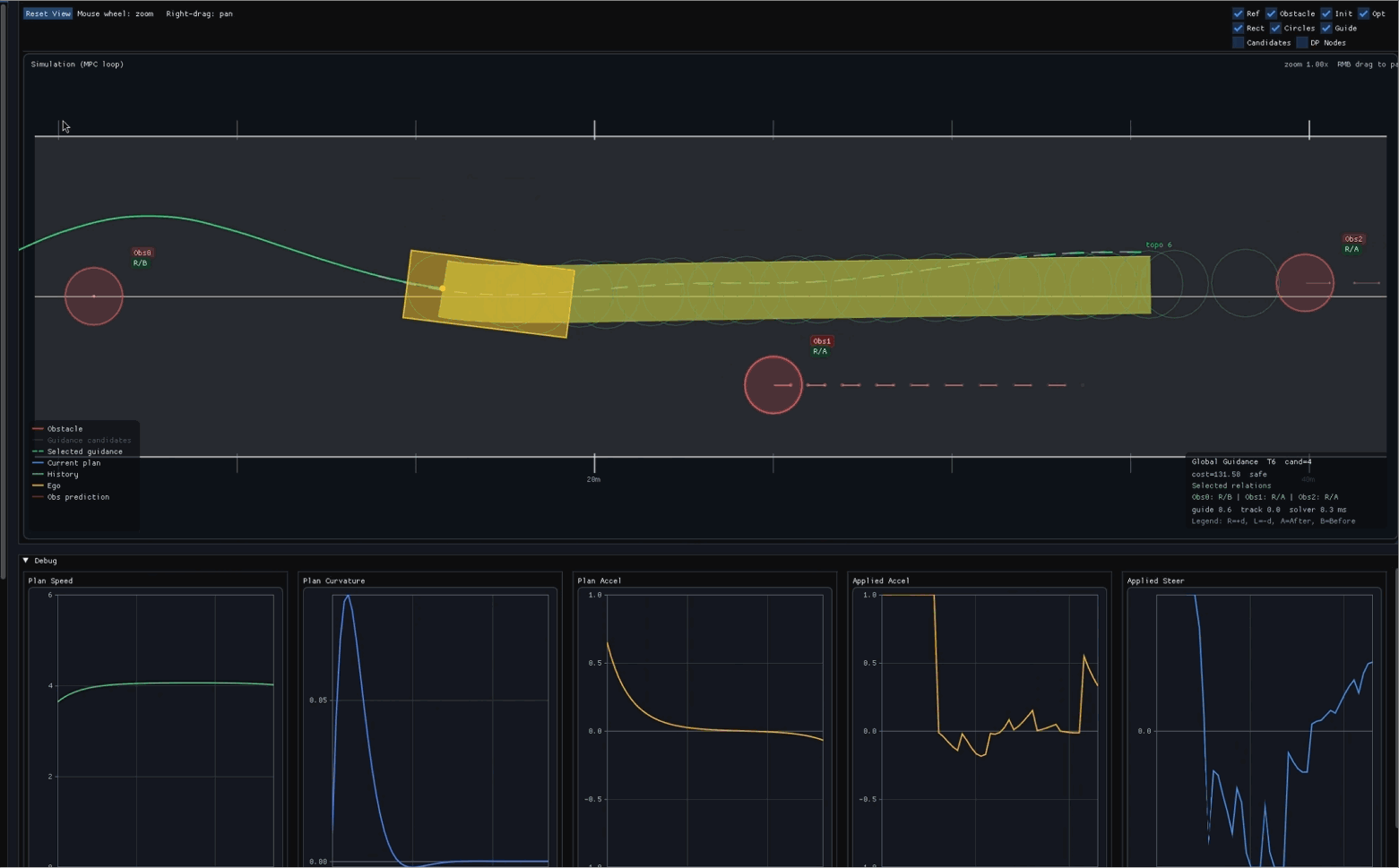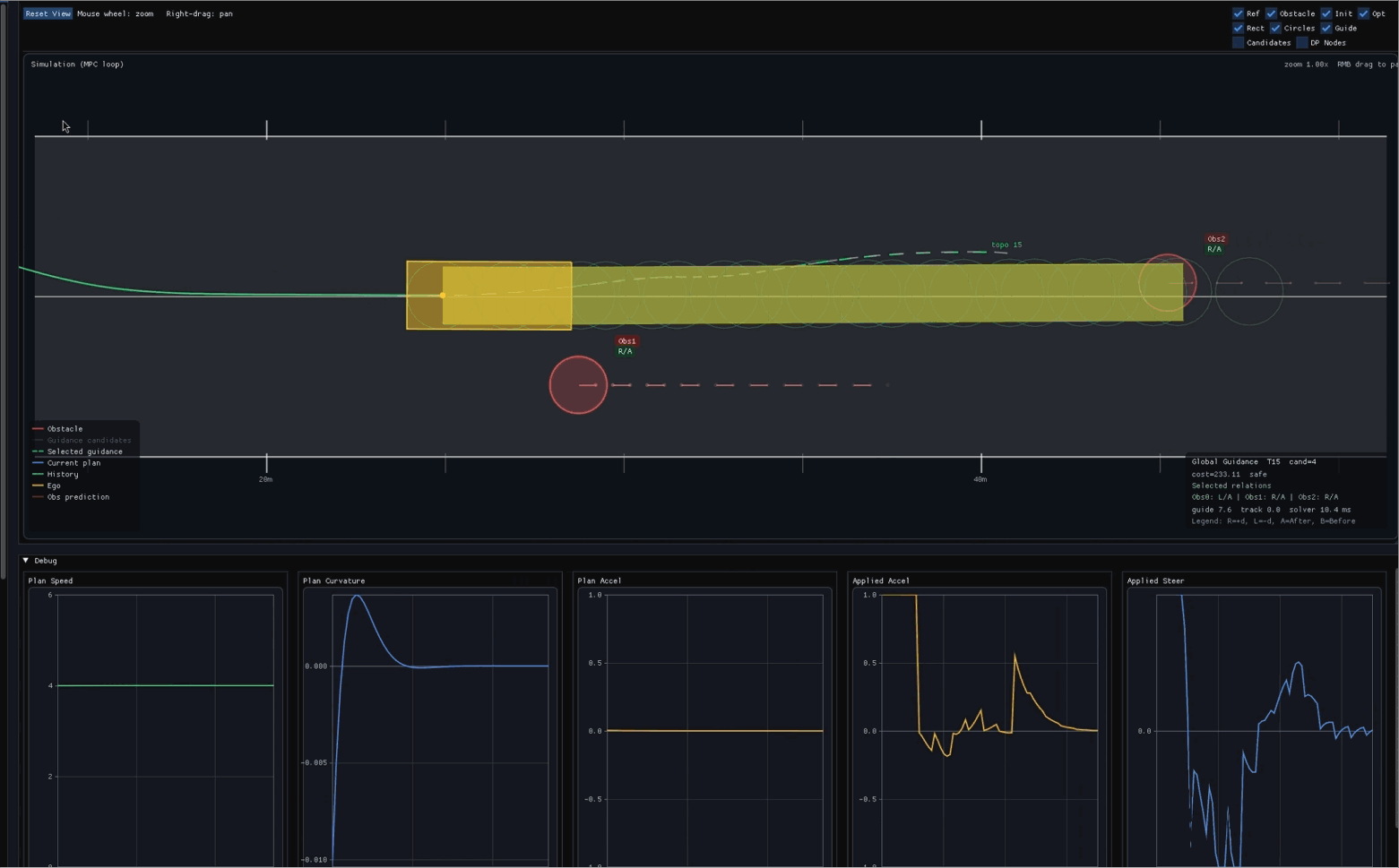
13.1. 架构继承关系
Llama-2(基座 LLM)
│
├─ Decoder-only Transformer,32层,hidden_dim=4096
├─ Causal Attention(只能看到前面的 token)
├─ 输出层 lm_head: Linear(4096 → 32000) 预测下一个词
│
↓
Vicuna-7B(指令微调)
│
├─ 在 Llama-2 上用对话数据微调
├─ 架构不变,只是权重更新
│
↓
LLaVA v1.5(加视觉能力)
│
├─ 加 CLIP ViT 作为视觉编码器
├─ 加 MLP 投影层:将视觉特征投影到 LLM 维度
├─ 序列格式:[BOS] + [视觉 token] + [文本 token]
├─ LLM 骨干仍然是 Vicuna-7B,架构不变
│
↓
Prismatic VLM(改进视觉编码)
│
├─ 将单 ViT 改为 双 ViT(SigLIP + DINOv2)
├─ 两路视觉特征拼接后投影,产生 512 个视觉 token
├─ 其余沿用 LLaVA 架构
│
↓
OpenVLA(加动作预测 —— 自回归离散方案)
│
├─ 加 ActionTokenizer:连续动作 → 256-bin 离散化 → token
├─ 动作预测方式:用 lm_head 自回归生成动作 token(和生成文字一样)
├─ 序列格式:[BOS] [视觉×512] [文本指令] → generate() → [动作 token×7]
├─ Loss:Cross-Entropy(离散分类)
├─ 推理:调用 generate(),逐 token 自回归生成,7个 token 需要 7 次前向传播
│
↓
OpenVLA-OFT(优化微调 —— 并行连续方案,核心转折点)
│
├─ 【动作生成】自回归 → 并行解码(一次前向传播输出所有动作)
├─ 【动作表示】离散 token → 连续数值
├─ 【输出层】 lm_head → MLP Action Head(新增独立网络)
├─ 【Loss】 Cross-Entropy → L1 回归
├─ 【输入改动】插入空 action embeddings 作为占位符
├─ 【注意力】 Causal Attention → Bidirectional Attention(动作位置改为双向)
├─ 【Action Chunking】支持 K 步动作块(如 K=8),一次输出 K×D 个动作值
├─ 【可选】FiLM 语言调制(OFT+ 版本,增强语言理解)
├─ 推理速度:比 OpenVLA 快 26×
│
↓
OmniVLA(本项目 —— 沿用 OFT 动作方案 + 多模态目标条件)
│
├─ 【沿用 OFT】MLP Action Head(MLPResNet_idcat,带 ResBlock)
├─ 【沿用 OFT】并行解码,一次前向传播输出 8 个 waypoint
├─ 【沿用 OFT】连续动作回归(MSE 替代 L1,效果类似)
├─ 【沿用 OFT】Action Chunking:8 waypoint × 4 维 = 32 个占位 token
│
├─ 【不同于 OFT】保留 Causal Attention(未改为双向)
├─ 【不同于 OFT】占位 token 的 embedding 清零(OFT 用空 embedding)
│
├─ 【OmniVLA 新增】多模态目标条件:视觉目标 / GPS位置目标 / 语言目标
├─ 【OmniVLA 新增】Pose Token:ProprioProjector 将 GPS 位置投影为 1 个 token
├─ 【OmniVLA 新增】Modality ID:在 Action Head 中拼接任务模态标识
├─ 【OmniVLA 新增】Modality Dropout:训练时随机丢弃目标模态
├─ 【OmniVLA 新增】平滑正则化:相邻 waypoint 差异的 MSE 作为额外 Loss
│
├─ 序列格式:[BOS] [视觉×512] [Pose×1] [文本指令] [动作占位×32] [EOS]
├─ Loss:MSE(主) + 目标物体 Loss + 平滑正则
└─ LLM 骨干仍然是 Vicuna-7B(Llama-2),架构未修改
有一个重要的实现细节不同:
- OpenVLA-OFT:将 causal attention mask 改为 bidirectional attention(双向注意力),让动作 token 之间可以互相看到
- OmniVLA:保留 causal attention mask,动作 token 只能看到前面的 token,不能看到后面的
这意味着 OmniVLA 的做法更保守——它没有修改 Llama-2 的注意力机制,而 OpenVLA-OFT 为了让并行解码更有效,专门把动作位置的注意力改成了双向的。
OpenVLA-OFT 是对原始 OpenVLA 的微调方案优化,核心改动正好就是 OmniVLA 继承的部分:
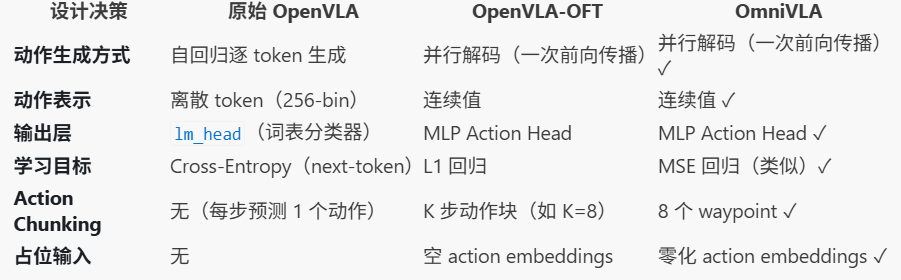
OmniVLA 沿用了 OFT 的动作预测框架,然后在此基础上加了自己的东西:
- 多模态目标条件:支持视觉/位置/语言三种目标输入(OFT 只有语言)
- Modality ID:在 Action Head 中拼接
modality_id(OFT 没有) - Pose Token:
ProprioProjector将 GPS 位置投影为 token(OFT 用的是 robot state projector,概念类似但用途不同) - MLP 结构不同:OmniVLA 用
MLPResNet_idcat(带 ResBlock),OFT 论文中描述的是更简单的 MLP - Loss 不同:OmniVLA 用 MSE + 平滑正则化,OFT 用 L1回归
13.1.1. 原版 OpenVLA:自回归 token 预测
原版 OpenVLA 把动作预测当作文本生成——和 ChatGPT 生成回答一样,一个 token 一个 token 地自回归输出:
训练时(teacher forcing):
输入: [BOS] [视觉...] [指令...] [动作1] [动作2] ... [动作31]
↓ ↓ ↓
预测: [动作2] [动作3] ... [动作32]
↑ ↑ ↑
用 cross-entropy loss 与真实 token ID 做对比
推理时(自回归生成):
[BOS] [视觉...] [指令...] → 预测动作1 → 把动作1拼上去 → 预测动作2 → ... → 逐个生成32个
在这种模式下,动作 token 的 embedding 必须有意义——因为"动作1 的 embedding"是模型预测"动作2"的输入。如果清零了,模型就失去了"上一步预测了什么"的信息,无法做自回归。
所以原版 OpenVLA 中这 256 个动作 bin 的 embedding 会被训练、会被更新,它们是自回归预测链条中不可或缺的一环。
13.1.2. OmniVLA:Action Head 回归
OmniVLA 改成了一次性前向传播 + MLP 回归:
训练和推理都是:
[BOS] [视觉...] [指令...] [占位×32] → LLM一次性处理 → 取动作位置的hidden states → Action Head(MLP) → 连续动作值
↑
清零(这些位置靠 positional encoding + attention 从上下文获取信息)
动作 token 不再是自回归链条的一部分,它们只是"留出 32 个位置"让 LLM 在这些位置生成 hidden state,再交给 MLP 回归出连续动作值。所以 embedding 清零没问题——甚至是必须的,避免无意义的词表 embedding 干扰。
13.2. 为什么omnivla没有像openvla那样,直接从预测token反解码出连续动作?
13.2.1. 原因 1:推理速度——1 次 vs 32 次前向传播
这是最直接的原因,对机器人实时控制至关重要。
OpenVLA(自回归):
预测动作1 → 拼到输入 → 预测动作2 → 拼到输入 → ... → 预测动作32
↑ ↑ ↑
第1次前向传播 第2次前向传播 第32次前向传播
一个 7B 参数的 LLM,前向传播一次大约需要 几十到几百毫秒。32 次 = 数秒级延迟。
OmniVLA(回归):
[所有输入一次性送入] → LLM 单次前向传播 → 取32个位置的hidden states → MLP → 32个动作值
↑
仅1次前向传播
延迟降低约 30 倍。对于需要 10Hz+ 控制频率的机器人来说,这是质的区别。
13.2.2. 原因 2:离散化精度损失
OpenVLA 把连续动作值(如 0.3847)映射到 256 个离散 bin 之一:
连续值空间 [-1, 1] 被切成 256 格
每格宽度 = 2/256 = 0.0078
真实动作: 0.3847
最近bin中心: 0.3828 (bin #177)
量化误差: 0.0019
这个误差在每个维度、每个时间步都存在,会累积
OmniVLA 的 MLP 直接回归连续值,没有量化误差:
hidden_states → MLP → 0.3847(直接输出浮点数)
13.2.3. 原因 3:动作维度之间的耦合
OmniVLA 预测 8 个 waypoint × 4 维 = 32 个值。
OpenVLA 的做法:逐个 token 生成,每个 token 对应一个维度。预测 x 方向速度时,只能看到之前已生成的 token(因为是自回归的),不能"偷看"同一时间步的 y 方向速度。
OmniVLA 的做法:
# L1RegressionActionHead_idcat.predict_action
def predict_action(self, actions_hidden_states, taskid):
batch_size = actions_hidden_states.shape[0]
rearranged_actions_hidden_states = actions_hidden_states.reshape(batch_size, NUM_ACTIONS_CHUNK, -1)
# ↑ 把 32 个 hidden states reshape 成 [B, 8, 4*4096]
# 每个 waypoint 同时看到 4 个维度的信息
action = self.model(rearranged_actions_hidden_states, taskid)
return actionMLP 把同一个 waypoint 的 4 个维度的 hidden states 拼在一起(reshape 操作),然后一次性预测出 4 维动作。这意味着 x、y、cos、sin 之间的关系(比如 cos²+sin²≈1)可以被 MLP 隐式学习。
13.2.4. 原因 4:Loss 函数更直接
OpenVLA:用 cross-entropy loss,优化的是"预测正确的 bin ID"。模型不知道 bin #177 和 bin #178 之间只差 0.0078——在 cross-entropy 看来,预测错一个 bin 和预测错 100 个 bin 的 loss 是一样的。
OmniVLA:用 MSE loss(看训练代码),直接优化预测值与真实值的距离:
loss = 1.0*torch.nn.MSELoss()(action_ref, predicted_actions) \
+ 0.1*torch.nn.MSELoss()(obj_pose_norm[lan_bool], predicted_actions[:,-1,0:2][lan_bool]) \
+ 0.1*torch.nn.MSELoss()(predicted_actions[:,0:-1], predicted_actions[:,1:])注意第三项 MSELoss(predicted_actions[:,0:-1], predicted_actions[:,1:])——这是一个平滑正则化,鼓励相邻 waypoint 之间的动作连续变化。这种 loss 在自回归 token 预测的框架下根本无法实现(因为预测的是 token ID,不是连续值)。
代价是什么? MLP Action Head 需要额外训练一个小网络(MLPResNet,约几百万参数),而且放弃了 LLM 自带的 token 预测能力(32064 维 logits 输出被闲置)。但对于需要实时控制的机器人场景来说,这个 trade-off 非常划算。
13.3. MLP 如何回归
13.3.1. 单个 hidden state 长什么样?
LLM(Vicuna-7B)的每个位置输出一个 4096 维的向量。序列中有 32 个动作占位 token,所以有 32 个 hidden state:
动作占位位置: [占位1] [占位2] [占位3] [占位4] [占位5] ... [占位32]
↓ ↓ ↓ ↓ ↓ ↓
hidden state: h_1 h_2 h_3 h_4 h_5 ... h_32
4096维 4096维 4096维 4096维 4096维 4096维
提取出来后的 shape 是 [B, 32, 4096]。
13.3.2. 32 个 token 怎么对应 8 个 waypoint?
常量定义:NUM_ACTIONS_CHUNK = 8,ACTION_DIM = 4,所以 8 × 4 = 32 个 token。
每 4 个连续的 hidden state 对应 1 个 waypoint。reshape 操作把它们拼接起来:
# predict_action() 第 129 行
rearranged = actions_hidden_states.reshape(batch_size, NUM_ACTIONS_CHUNK, -1)
# [B, 32, 4096] → [B, 8, 4*4096] = [B, 8, 16384]
具体过程:
reshape 前: [B, 32, 4096]
token 1: [h_1] ─┐
token 2: [h_2] ─┤── 拼接 → waypoint 1: [h_1 | h_2 | h_3 | h_4] = 16384 维
token 3: [h_3] ─┤
token 4: [h_4] ─┘
token 5: [h_5] ─┐
token 6: [h_6] ─┤── 拼接 → waypoint 2: [h_5 | h_6 | h_7 | h_8] = 16384 维
token 7: [h_7] ─┤
token 8: [h_8] ─┘
...
token 29: [h_29] ─┐
token 30: [h_30] ─┤── 拼接 → waypoint 8: [h_29 | h_30 | h_31 | h_32] = 16384 维
token 31: [h_31] ─┤
token 32: [h_32] ─┘
reshape 后: [B, 8, 16384]
13.3.3. MLP 是逐个 waypoint 回归吗?需要回归 8 次?
MLP 利用 PyTorch 的张量并行,一次调用就同时处理 8 个 waypoint。
看 MLPResNet_idcat.forward() 的实际执行:
def forward(self, x, taskid):
# x 的 shape: [B, 8, 16384] ← 8 个 waypoint 在 dim=1 上并排
x = self.layer_norm1(x) # [B, 8, 16384] LayerNorm 对最后一维操作
x = torch.cat((x, taskid...), axis=2) # [B, 8, 16385] 拼上 modality_id
x = self.fc1(x) # [B, 8, 4096] Linear(16385, 4096) 对每个 waypoint 独立作用
x = self.relu(x) # [B, 8, 4096]
x = block1(x) # [B, 8, 4096] ResBlock
x = block2(x) # [B, 8, 4096] ResBlock
x = self.layer_norm2(x) # [B, 8, 4096]
x = self.fc2(x) # [B, 8, 4] Linear(4096, 4) → 每个 waypoint 输出 4 维
return x # [B, 8, 4]nn.Linear 作用于张量的最后一维。当输入是 [B, 8, 16384] 时,它对 8 个 waypoint 共享同一组权重,但在计算上是并行的——就像 batch 维度一样。
所以准确地说:
- 逻辑上:是的,每个 waypoint 独立经过同一个 MLP(权重共享)
- 计算上:不是 8 次调用,而是 1 次矩阵乘法,8 个 waypoint 并行处理
- 类比:就像
Linear处理 batch_size=32 的数据不需要循环 32 次一样,dim=1 上的 8 个 waypoint 也不需要循环
一次矩阵乘法:
[B, 8, 16384] × [16384, 4096] = [B, 8, 4096]
↑ ↑
8个waypoint并排 8个waypoint同时算完
完整数据流程:
LLM 输出的 hidden states
[B, 32, 4096]
│
│ reshape: 每4个token拼成1个waypoint
↓
[B, 8, 16384] ← 8个waypoint,每个16384维(4个4096拼接)
│
│ LayerNorm + concat(modality_id)
↓
[B, 8, 16385]
│
│ Linear(16385 → 4096) + ReLU
↓
[B, 8, 4096]
│
│ ResBlock × 2
↓
[B, 8, 4096]
│
│ LayerNorm + Linear(4096 → 4)
↓
[B, 8, 4] ← 8个waypoint,每个4维 (y, x, cosθ, sinθ)
13.4. 自回归和一次性输出
同样都是基于llama 2,为什么openvla是autoregressive的,而omnivla不是?为什么openvla需要一个 token 一个 token 地生成动作串,而omnivla可以一次性就输出动作串? Llama-2 本身并不是"只能自回归"的——自回归是一种使用方式,不是模型的固有限制。
13.4.1. 先理解 Llama-2 的前向传播到底做了什么
Llama-2 的 forward 本质上就是:给定一条序列,对每个位置并行计算 hidden state。
输入: [token_1] [token_2] [token_3] [token_4] [token_5]
↓ ↓ ↓ ↓ ↓
LLM: 并行处理所有位置(通过 causal attention mask 控制可见范围)
↓ ↓ ↓ ↓ ↓
输出: [h_1] [h_2] [h_3] [h_4] [h_5] ← hidden states
↓ ↓ ↓ ↓ ↓
lm_head: [logits_1] [logits_2] [logits_3] [logits_4] [logits_5] ← 词表概率
一次 forward 就已经把所有位置的 hidden state 都算出来了。这在训练时每个 batch 都在发生——teacher forcing 就是一次性把整个序列(含正确答案)喂进去,一次 forward 算出所有位置的 loss。
13.4.2. OpenVLA 为什么需要自回归?
OpenVLA 把动作预测当成了文本生成任务——它用的是 lm_head(最后那个 Linear(4096, 32064) 分类器)来预测动作 token:
# openvla.py
generated_ids = super().generate(input_ids=..., max_new_tokens=7)
generate() 做的事情是:
第 1 步: 输入 [prompt...],lm_head 预测下一个 token → action_1
第 2 步: 输入 [prompt... action_1],预测 → action_2
第 3 步: 输入 [prompt... action_1 action_2],预测 → action_3
...
为什么必须一个一个来?
因为 lm_head 在位置 预测的是"位置 应该是什么 token"。在推理时,位置 的 token 还不存在——你不知道该在那个位置放什么输入。你必须先得到 action_1 的预测结果,才能把它作为输入去预测 action_2。
这就是自回归的本质约束:当你依赖模型自己的预测结果作为下一步的输入时,就只能串行生成。
13.3.4. OmniVLA 为什么可以一次性输出?
OmniVLA 做了一个关键的设计转变——它不用 lm_head,也不需要模型"预测"动作 token 是什么。
它的做法是:推理前就把 32 个占位 token 全部放进输入序列。
OpenVLA 推理时的输入: [BOS] [视觉] [指令] ← 动作 token 还不存在,需要逐个生成
OmniVLA 推理时的输入: [BOS] [视觉] [指令] [占位×32] ← 32 个位置已经在那了(虽然 embedding 被清零)
因为所有位置都已经有了输入,LLM 可以一次 forward 把所有位置的 hidden state 都算出来:
OmniVLA 一次 forward:
[BOS] [视觉...] [指令...] [零] [零] [零] ... [零] ← 32 个清零的占位
↓ ↓ ↓ ↓ ↓ ↓ ↓
h_0 h_1... h_n... h_a1 h_a2 h_a3 ... h_a32 ← 所有 hidden states 一次算出
↓ ↓ ↓ ↓
Action Head (MLP) → 连续动作值
OmniVLA 不需要知道"动作 token 是什么",因为它根本不用 token 来表示动作。它只需要 LLM 在这些位置产出有意义的 hidden state——这些 hidden state 通过 causal attention 聚合了前面视觉和文本的全部信息,Action Head 再从中回归出连续动作值。
13.5. 基础概念
13.5.1. 前置概念
机器学习里,一个模型大致有三件事要说清楚:
(1) 模型输出什么
比如输出:
- 一个类别概率分布
- 一个连续数值
- 一个 token 序列
- 一段连续动作序列 这叫 输出形式 / 预测目标
(2) 模型怎么输出
比如:
- 一次性直接输出
- 一个一个往后生成
- 用 MLP 从 hidden state 映射出来 这叫 生成方式 / 结构形式
(3) 训练时怎么衡量错得多不多
比如:
- Cross-entropy
- MSE
- L1 loss 这叫 损失函数
13.5.2. 怎么预测
13.5.2.1. 自回归(Autoregressive)
自回归不是损失函数,而是一种生成方式,所以“自回归”描述的是生成过程,不是“输出是离散还是连续”。 含义:逐个生成,后一个依赖前一个。 就是你选中的这段代码在做的事:
generated_ids = super(PrismaticVLM, self).generate(
input_ids=input_ids,
max_new_tokens=self.get_action_dim(unnorm_key), # 7个token,逐个生成
)generate() 内部做的事:
第1步:输入 [prompt] → 模型预测 → 采样得到 token_1
第2步:输入 [prompt, token_1] → 模型预测 → 采样得到 token_2
第3步:输入 [prompt, token_1, token_2] → 模型预测 → 采样得到 token_3
...重复7次
就像写作文——写完第一个字才能写第二个字,因为你要根据前文决定后文。ChatGPT 回复你的时候就是自回归的,一个字一个字蹦出来。
13.5.2.2. MLP 回归(MLP Regression)
含义:用一个神经网络(MLP = Multi-Layer Perceptron,多层感知机)直接算出一个连续数值。
输入: hidden_state [16384维向量]
↓
Linear(16384 → 4096) + ReLU ← 第1层
↓
ResBlock × 2 ← 中间层
↓
Linear(4096 → 4) ← 最后一层
↓
输出: [0.32, -0.15, 0.87, 0.49] ← 4个连续数值,直接就是动作
13.5.2.3. L1 回归是什么
这个词经常被说得不严谨。严格来说,“L1 回归”通常指: 回归任务中使用 L1 loss(绝对值误差)作为损失函数
| 自回归 | MLP 回归 | |
|---|---|---|
| 输出类型 | 离散 token(从词表中选一个词) | 连续数值(直接输出小数) |
| 输出过程 | 逐个生成,串行 | 一次计算,并行 |
| 类比 | 做选择题(从 256 个选项中选 1 个) | 做填空题(直接写一个数字) |
13.5.2.4. 什么是回归
这是机器学习里的基本术语。 定义:回归 = 预测连续数值 例如:
- 预测一个标量:速度
- 预测一个向量:
- 预测一个序列:
只要输出是连续实数,通常就叫回归。
13.5.3. 怎么算错误(Loss 函数)
Loss 函数衡量"模型预测"和"正确答案"之间的差距。差距越大,Loss 越大,模型就调整更多。
13.5.3.1. Cross-entropy(交叉熵)
Cross-entropy 通常用于模型输出是离散类别分布时,也就是分类问题,或者 token prediction 问题。例如:
- 图片是猫/狗/鸟
- 下一个 token 是哪个词
- 动作 token 应该是第几个 bin 如果真值是某个离散类别,那么最常见的损失就是 cross-entropy loss。
它在 token 预测里的意义: LLM 或 OpenVLA 原始版中,模型输出的是词表上的 logits,softmax 后得到每个 token 的概率。比如真实动作 token 是 132,模型若给 token 132 很高概率,则损失小;如果给别的 token 高概率,则损失大。
Cross-entropy 适合:
- 分类任务
- 离散 token 预测
- 自回归语言建模
- 离散化动作建模 不适合直接监督连续浮点数。
场景:模型输出一个概率分布(比如 256 个 bin 各自的概率),正确答案是其中一个 bin。
模型输出(概率分布):
bin_0: 0.01
bin_1: 0.02
...
bin_127: 0.70 ← 模型觉得最可能是这个
...
bin_200: 0.03
bin_255: 0.01
正确答案: bin_130
Cross-Entropy Loss = -log(模型给正确答案的概率)
= -log(0.005) ← 模型只给了 bin_130 0.5% 的概率
= 5.3 ← Loss 很大,说明预测得不好
OpenVLA 用它:因为 OpenVLA 把动作离散化成 256 个 bin,预测动作就是"从 256 个选项中选一个"——这就是分类问题。
13.5.3. 2. MSE(Mean Squared Error,均方误差)—— 用于连续回归
场景:模型直接输出一个数值,正确答案也是一个数值。
模型预测: [0.32, -0.15, 0.87, 0.49]
正确答案: [0.30, -0.10, 0.90, 0.50]
MSE = 平均((0.32-0.30)² + (-0.15-(-0.10))² + (0.87-0.90)² + (0.49-0.50)²)
= 平均(0.0004 + 0.0025 + 0.0009 + 0.0001)
= 0.000975
OmniVLA 用它:torch.nn.MSELoss()(action_ref, predicted_actions)
13.5.3.3. L1 回归(L1 Regression)—— 也用于连续回归
场景:和 MSE 一样,模型输出数值,正确答案也是数值。
模型预测: [0.32, -0.15, 0.87, 0.49]
正确答案: [0.30, -0.10, 0.90, 0.50]
L1 = 平均(|0.32-0.30| + |-0.15-(-0.10)| + |0.87-0.90| + |0.49-0.50|)
= 平均(0.02 + 0.05 + 0.03 + 0.01)
= 0.0275
算每个维度的误差的绝对值,取平均。不做平方——对大误差和小误差一视同仁。 OpenVLA-OFT 用它。
MSE vs L1 的区别
| MSE | L1 | |
|---|---|---|
| 对大误差 | 惩罚更重(平方放大) | 线性惩罚 |
| 对异常值 | 敏感(容易被带偏) | 更鲁棒 |
| 训练效果 | 倾向于学到"平均值" | 倾向于学到"中位数" |
13.5.3.4. 平滑正则化(Smoothness Regularization)
OmniVLA 特有的额外 Loss 项:
# train_omnivla.py
loss = 1.0 * MSE(action_ref, predicted_actions) # 主Loss:预测要准
+ 0.1 * MSE(obj_pose, predicted_actions[:,-1,0:2]) # 目标Loss
+ 0.1 * MSE(predicted_actions[:,0:-1], predicted_actions[:,1:]) # 平滑Loss第三项的含义——相邻 waypoint 之间不要差太多:
8个waypoint: [wp1] [wp2] [wp3] [wp4] [wp5] [wp6] [wp7] [wp8]
平滑Loss = MSE(wp1, wp2) + MSE(wp2, wp3) + ... + MSE(wp7, wp8)
如果: wp1=[0.1, 0.2] wp2=[0.8, 0.9] → 差距大 → Loss大 → 惩罚
如果: wp1=[0.1, 0.2] wp2=[0.12, 0.22] → 差距小 → Loss小 → 鼓励
机器人的未来轨迹应该是平滑的曲线,不应该突然跳变。这个 Loss 就是在说"相邻的路径点要连续、不要抖动"。
总结:
OpenVLA: 自回归生成离散 token + Cross-Entropy Loss
↓ ↓
"从256个选项中选1个" "选对了吗?概率给够了吗?"
OpenVLA-OFT: MLP 回归连续值 + L1 Loss
↓ ↓
"直接算出一个数" "|预测值 - 真实值| 的绝对差"
OmniVLA: MLP 回归连续值 + MSE Loss + 平滑正则
↓ ↓
"直接算出一个数" "(预测值 - 真实值)² + 相邻waypoint要平滑"