演示视频
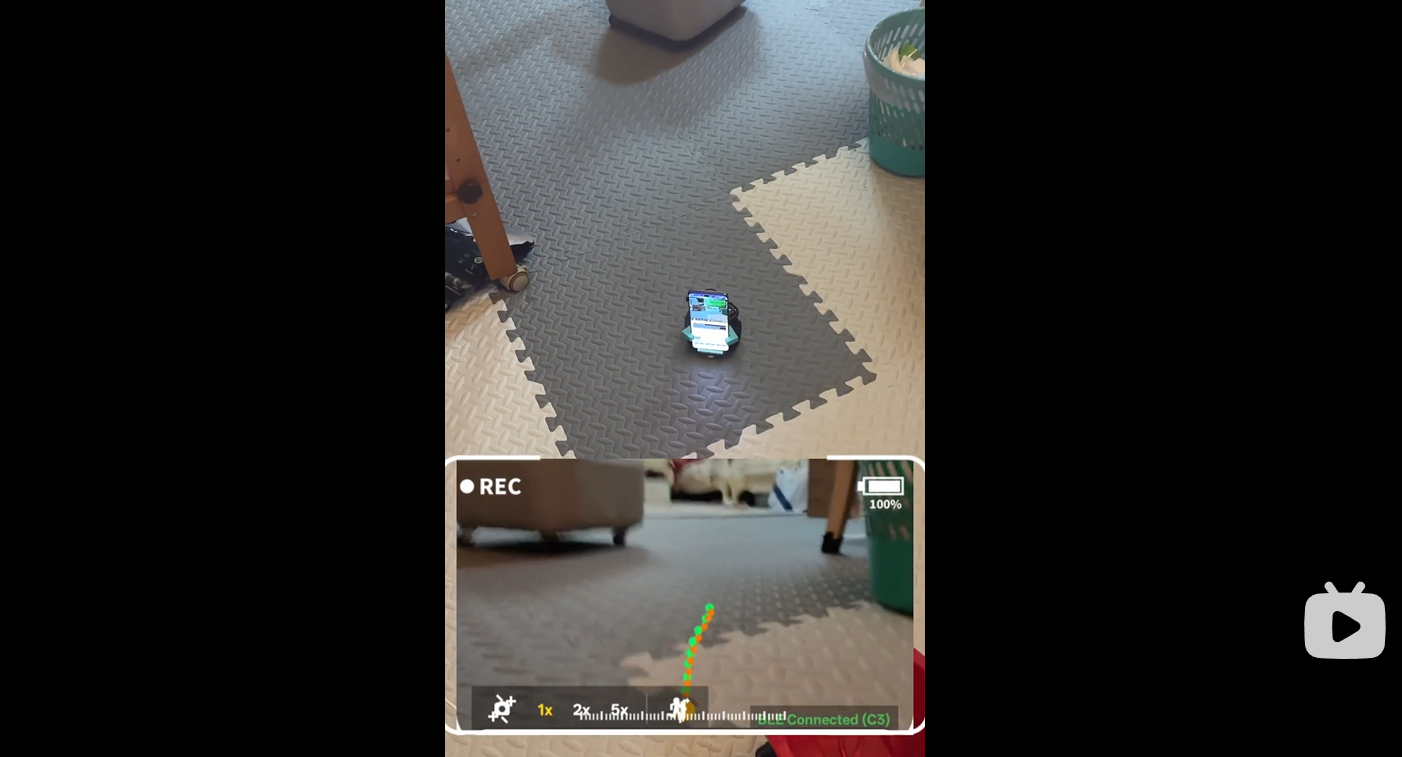
一台 Android 手机 + ESP32 底盘 + AutoDL GPU,完整跑通"语音 → 视觉感知 → VLA 导航"端到端链路。视频里展示了 ahbot 当前 P1.5 阶段的实测效果。
开源地址: https://github.com/ahrs365/ahbot-vla
这是什么
ahbot 把四类成熟开源模块粘合成一台能听懂中文的导航机器人:
| 角色 | 用什么 | 解决什么 |
|---|---|---|
| 大脑(决策) | OpenClaw + qwen-turbo | 听用户说什么、调用工具、自然语言回复 |
| 视觉导航 | OmniVLA | image / language / GPS goal → v / ω |
| 视觉感知 | YOLO-World v2 | 开放词表物体检测("水瓶"、"红色椅子") |
| 实时控制 | Android + ESP32 | WebRTC 拉视频 + BLE 50/100Hz PID |
整个系统通过一组强边界把这些模块组织在一起:LLM 不进控制环、Bridge 不调 LLM、Plugin 不写业务逻辑、ESP32 不联网。详细原则见 AGENTS.md。
一句话演示
用户:去最近那把椅子
↓
OpenClaw:好的,去最近的椅子
↓ ahbot_set_goal_from_object(object="chair", position_hint="closest")
↓ ahbot_nav_start(goal_kind="goal_image", goal_image_id=...)
↓
机器人:自动检测 → 选最大 bbox → 切目标图 → OmniVLA 导航 → 到达
三种导航模式
| Goal kind | 用法 | 例子 |
|---|---|---|
language | 给 OmniVLA 一句英文 | "Move to chair" |
gps_route | 已知 GPS 路点 | route_id + waypoints |
goal_image | 给一张目标图 | 通常由 set_goal_from_object 自动生成 |
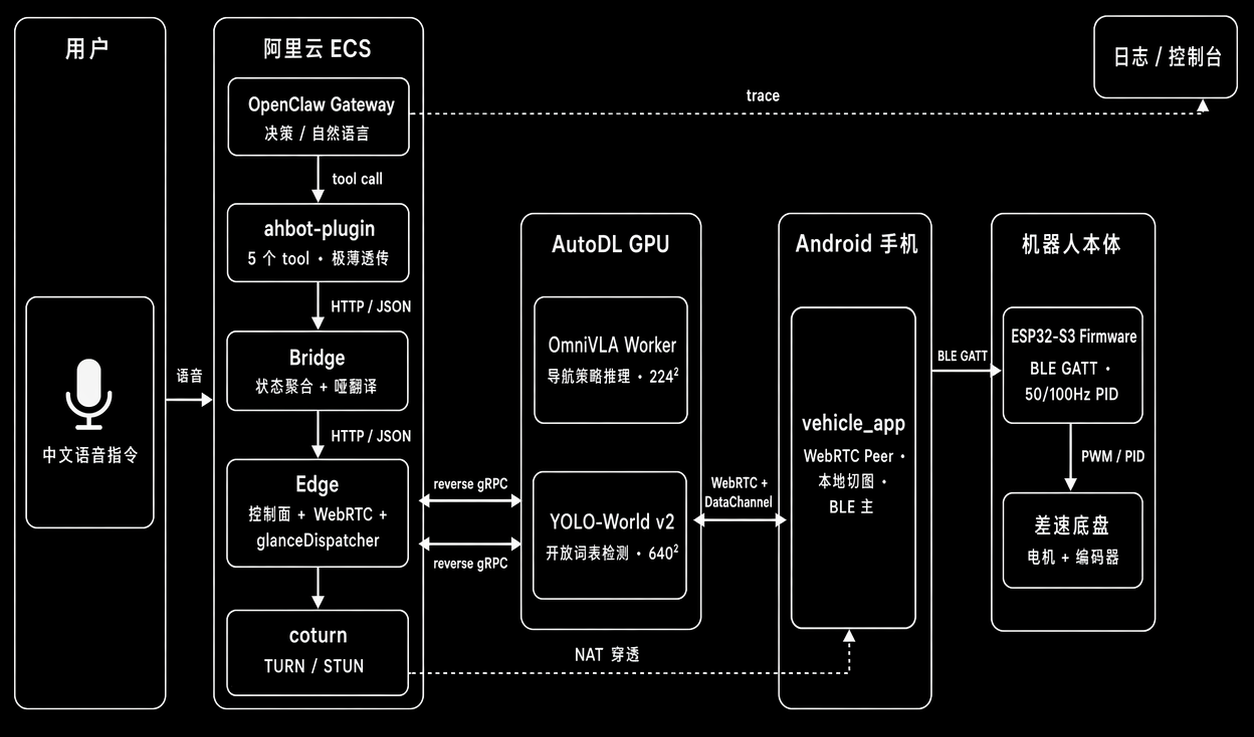
系统架构
部署拓扑
协议矩阵
| 边 | 协议 | 频率 | 用途 |
|---|---|---|---|
| 用户 ↔ OpenClaw | 飞书 webhook(已接入) | 对话级 | 自然语言交互 |
| OpenClaw → plugin | 进程内 tool call | 秒级 | 调 5+ 个工具 |
| plugin → Bridge | HTTP 127.0.0.1 | 秒级 | 透传参数 |
| Bridge → Edge | HTTP 127.0.0.1 | 秒级 | 控制面命令 |
| Edge ↔ Worker | reverse gRPC | 1–5 Hz | 推理(worker 主动出站) |
| Edge ↔ App | WebRTC + DataChannel | 30 fps + 事件 | 视频流 + 控制信令 |
| App → ESP32 | BLE GATT | 50 Hz | v / ω 实时控制 |
底盘核心硬件

- 电机驱动模块:L298N
- 电机:N20 带编码器电机
- 主控板:ESP32-C3
路线图
详见 docs/ROADMAP.md。
参考与启发
ahbot 在设计阶段研读过四个走"让大模型当机器人主脑"路线的兄弟项目。它们提供了非常有价值的设计样本,但都验证了同一件事:让 OpenClaw 看图后自主拆解多步任务,目前还达不到生产可用。
| 项目 | 出品方 | 核心设想 | ahbot 借鉴 | 未沿用的原因 |
|---|---|---|---|---|
| ABot-Claw | 高德 AMAP CV Lab | OpenClaw + VLAC (Vision-Language-Action-Critic) loop,多模态记忆驱动 multi-agent | 工程分层:robot / service / openclaw 三段切分 | VLAC 闭环未达稳定生产;ahbot 取消 critic / mission-orchestrator |
| Tidybot-Universe | Tidybot Services | Composable skill 库 + Claude Code 驱动 pick/place/clean 任务链 | "skill 化"思想,用于 OpenClaw workspace 的 SKILL.md 体系 | 多步技能链对幻觉敏感;ahbot 收敛到单 tool round-trip |
| RoboClaw | SJTU MINT Lab | 沿 OpenClaw 路线的开源 embodied 助手(CLI + Mobile) | 极薄 plugin + 命令行驱动的开发体验 | 早期阶段,端到端未跑通;ahbot 限定 P1 范围更死 |
| dimos | dimensionalOS | The Agentive Operating System for Physical Space,CLI + MCP + Blueprints | CLIP-based 空间记忆思路(保留到 P2) | 系统较重,超出 P1 单兵作战的工程预算 |
详细的借鉴点:
- ABot-Claw — 高德 AMAP CV Lab 出品。提出 VLAC (Vision-Language-Action-Critic) 闭环 + 多模态记忆驱动的 multi-agent embodied 框架。
- Tidybot-Universe — Tidybot Services 出品。提倡把机器人能力拆成 composable skill 库,用 Claude Code 驱动 pick / place / clean 任务链。
- RoboClaw — SJTU MINT Lab 出品。沿 OpenClaw 路线的开源 embodied intelligence assistant,覆盖 CLI 与 Mobile 入口。
- dimos — dimensionalOS 出品。定位 "The Agentive Operating System for Physical Space",提供 CLI + MCP + Blueprints + CLIP 空间记忆等基础设施。
Vibe Coding 指南
本项目的代码 100% 由 AI 协作产出(主力:
claude-opus-4.7、gpt-5.4-codex、composer-2,辅以人类 reviewer 把关方向)。仓库里所有规则、SKILL、DECISION 都是为"AI + 人类"双驾驶架构设计的。 如果你打算用 Cursor / Claude Code / Codex / Aider 等工具继续开发本项目,下面的指令请直接读完再动手。
给 AI 协作者的硬规则如下:
AGENTS.md— 项目根规则。§3 强制边界和 §4 性能契约违反一条,就别提 PRdocs/CURRENT_PHASE.md— 确认你想做的事在当前阶段范围内(P1.5 = 语音导航 + YOLO 视觉感知)docs/ARCHITECTURE.md— 八层分层和职责docs/DECISIONS.md— 历史已决议过的方向。不要重新发明已经否决的方案- 改哪一层就读哪一层的局部规则:
- 改 Bridge / plugin →
docs/BRIDGE_API_V1.md- 改 OpenClaw 行为 →integrations/openclaw/workspace/AGENTS.md+docs/SKILL_AUTHORING.md- 改部署脚本 →docs/deployment/{alicloud,autodl}.md-
License
鸣谢
直接依赖
- OmniVLA — Hirose, Glossop, Shah, Levine. OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation. ICRA 2026. arXiv:2509.19480
- YOLO-World — 开放词表目标检测
- OpenClaw — Personal AI assistant,Agent runtime 灵感来源
- 阿里云 / 百炼 — qwen-turbo LLM
- AutoDL — GPU 算力
评论
加入讨论
登录或注册后即可发表评论,与其他学习者交流
0 条评论
加载评论中...