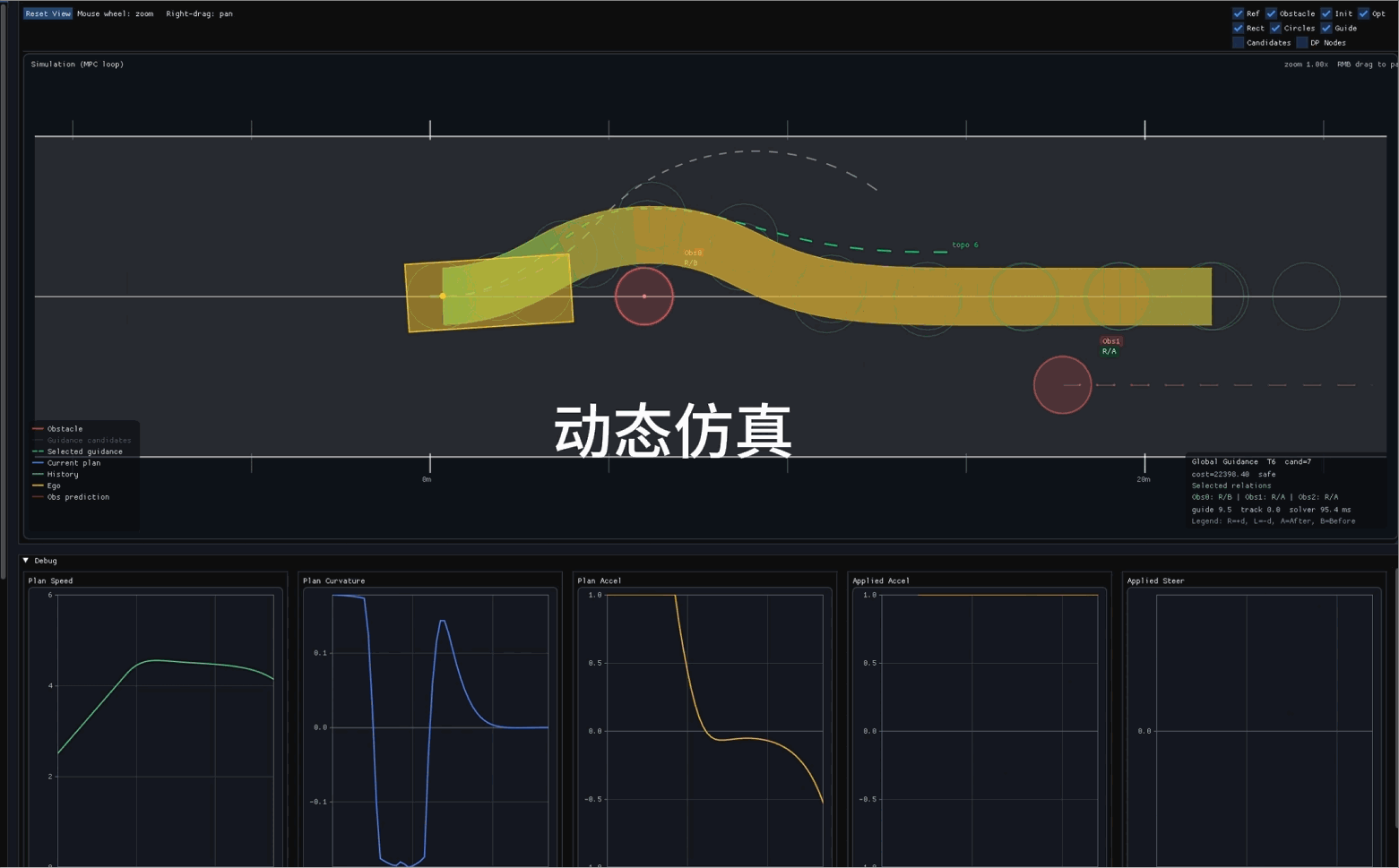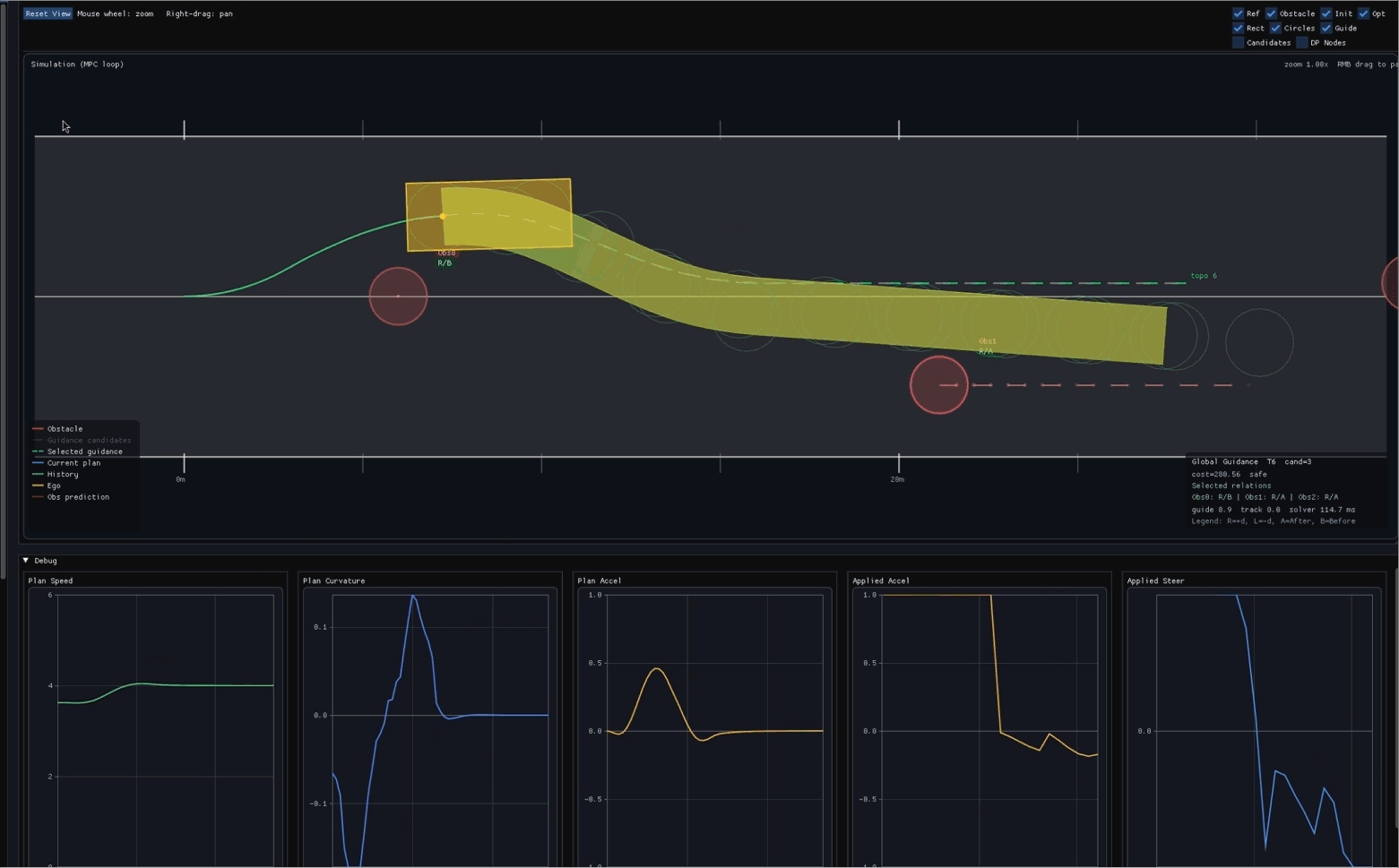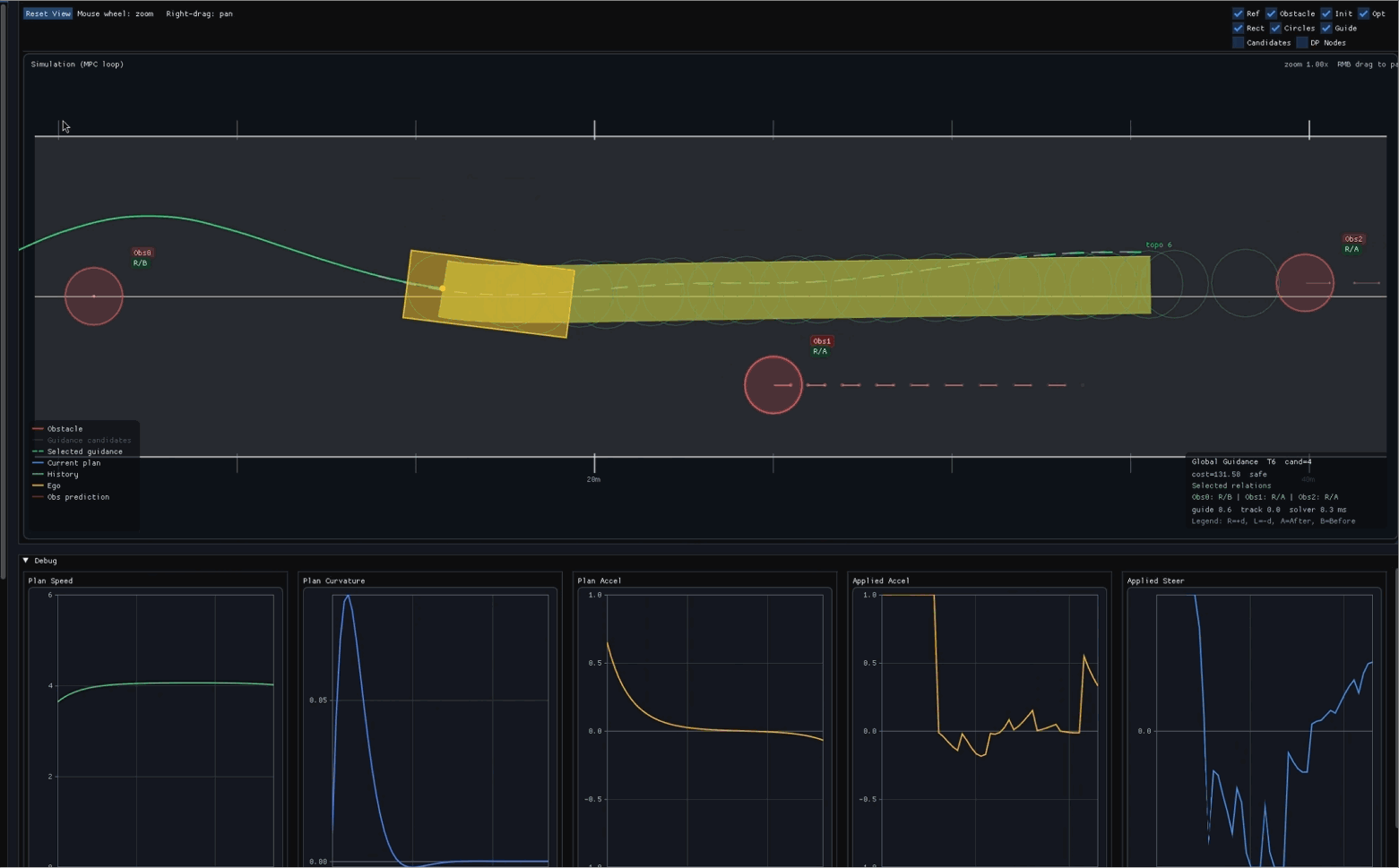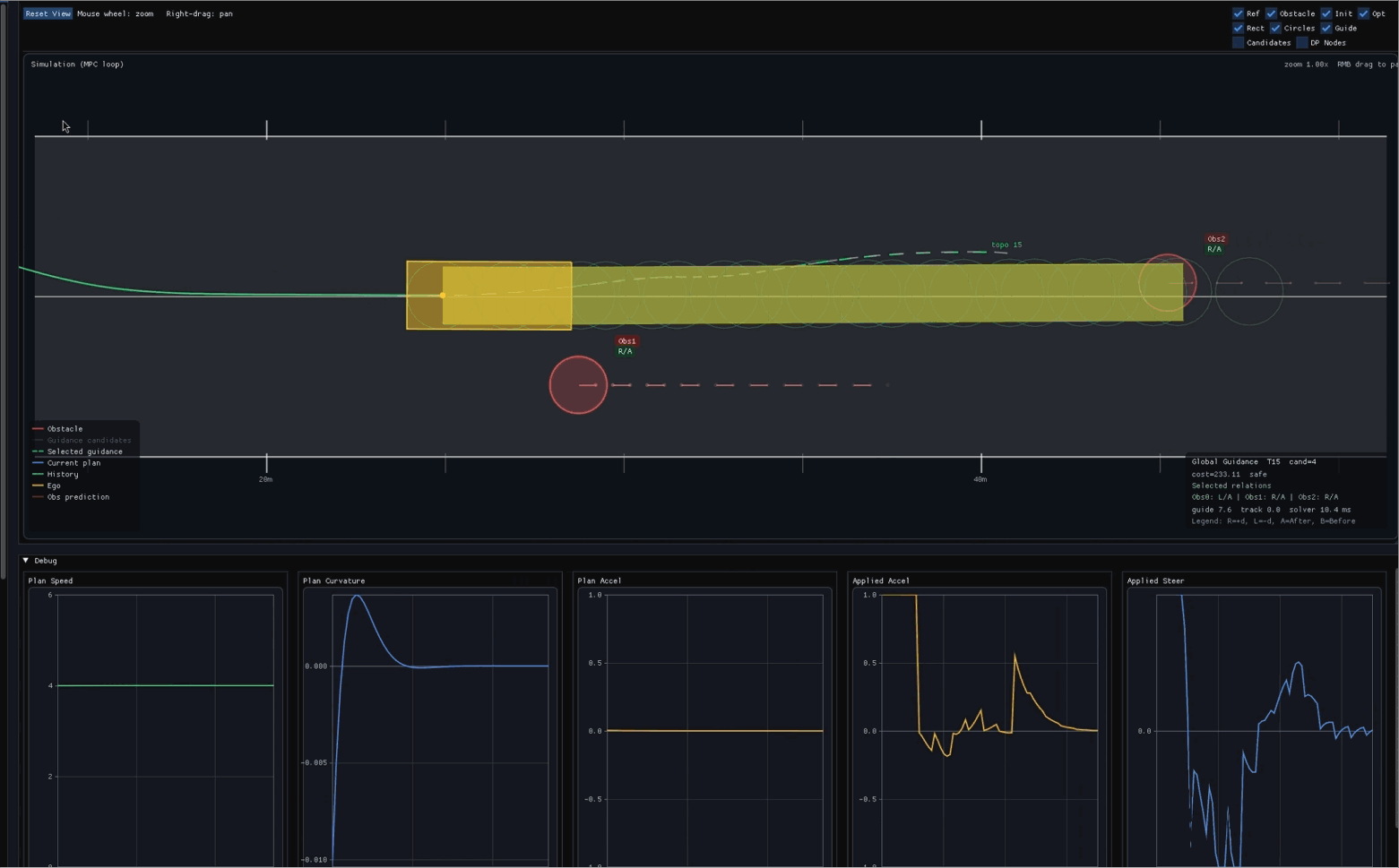

目标:理解轨迹优化的基本组成,能对给定控制序列做前向仿真并计算代价
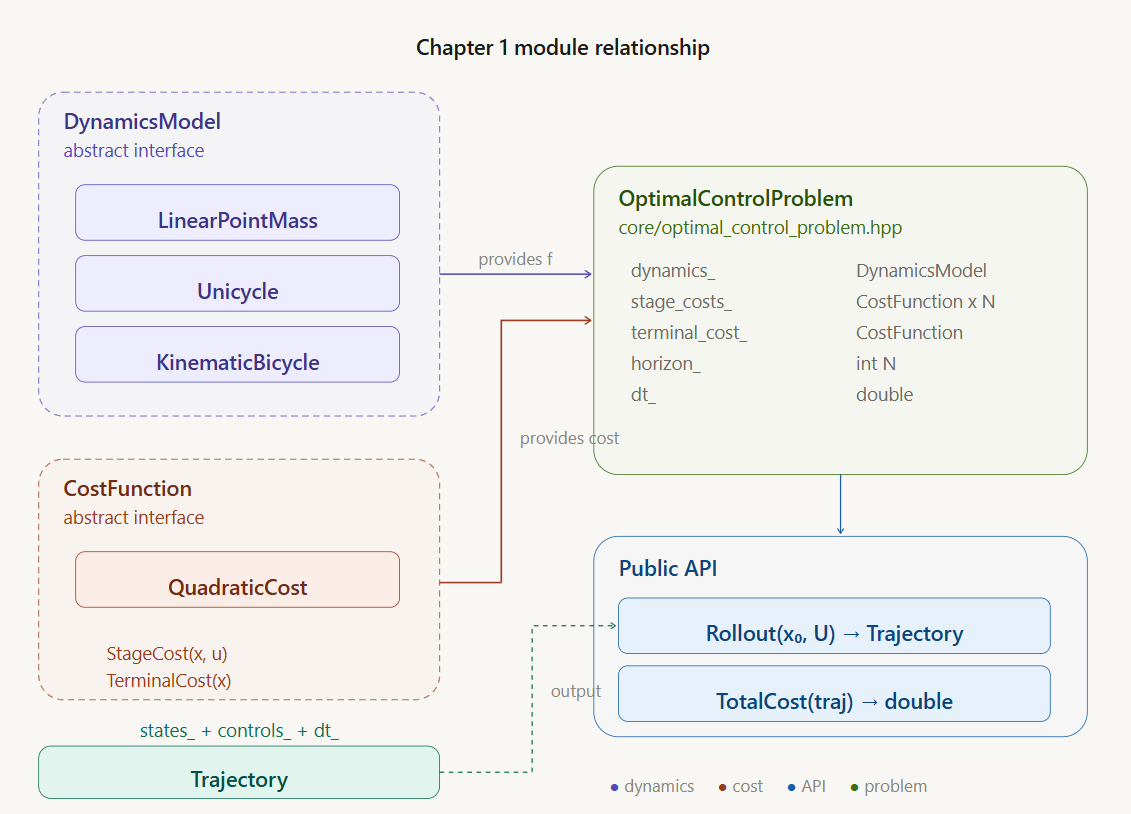
1.1 什么是轨迹优化
1.1.1 基础概念
在机器人和自动驾驶领域,我们经常面对这样的问题:如何让一个系统从初始状态移动到目标状态,同时最小化某种代价(如能量、时间、偏差)?
这就是轨迹优化(Trajectory Optimization)的核心问题。
一个最简单的例子:你开车从 A 点到 B 点,希望方向盘转动最小、油门最平稳——这就是一个轨迹优化问题。
1.1.2 连续时间表述
数学上,轨迹优化问题可以写成:
其中:
- 是状态(如位置、速度、朝向)
- 是控制量(如加速度、方向盘转角)
- 是动力学模型,描述系统如何演化
- 是阶段代价,衡量每一时刻的"好坏"
- 是终端代价,衡量最终状态的"好坏"
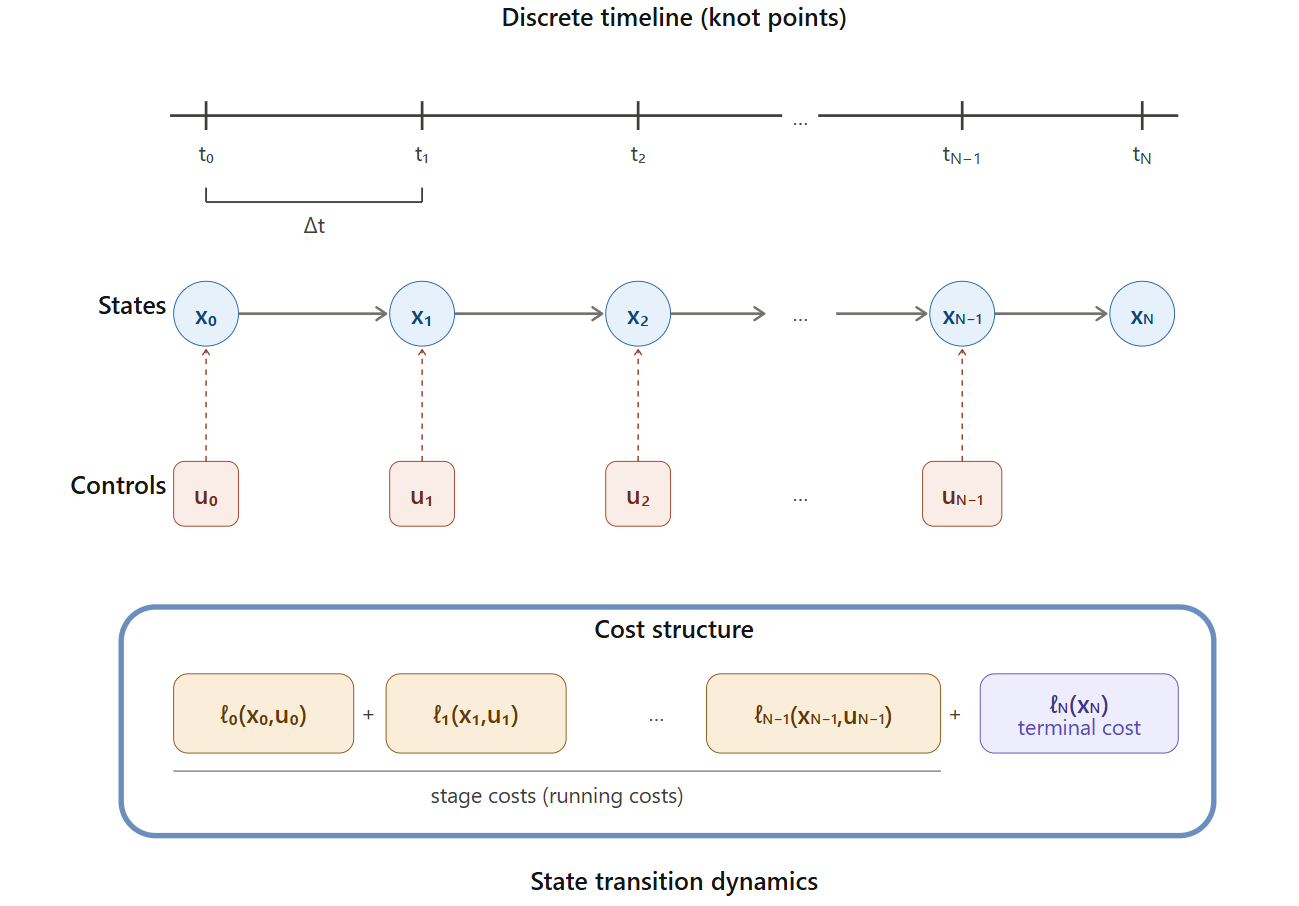
1.1.3 离散时间表述
计算机无法处理连续时间,所以我们将时间离散化为 个步长,每步时长 :
离散化后,轨迹变成了一系列离散点,称为 knot point(节点):
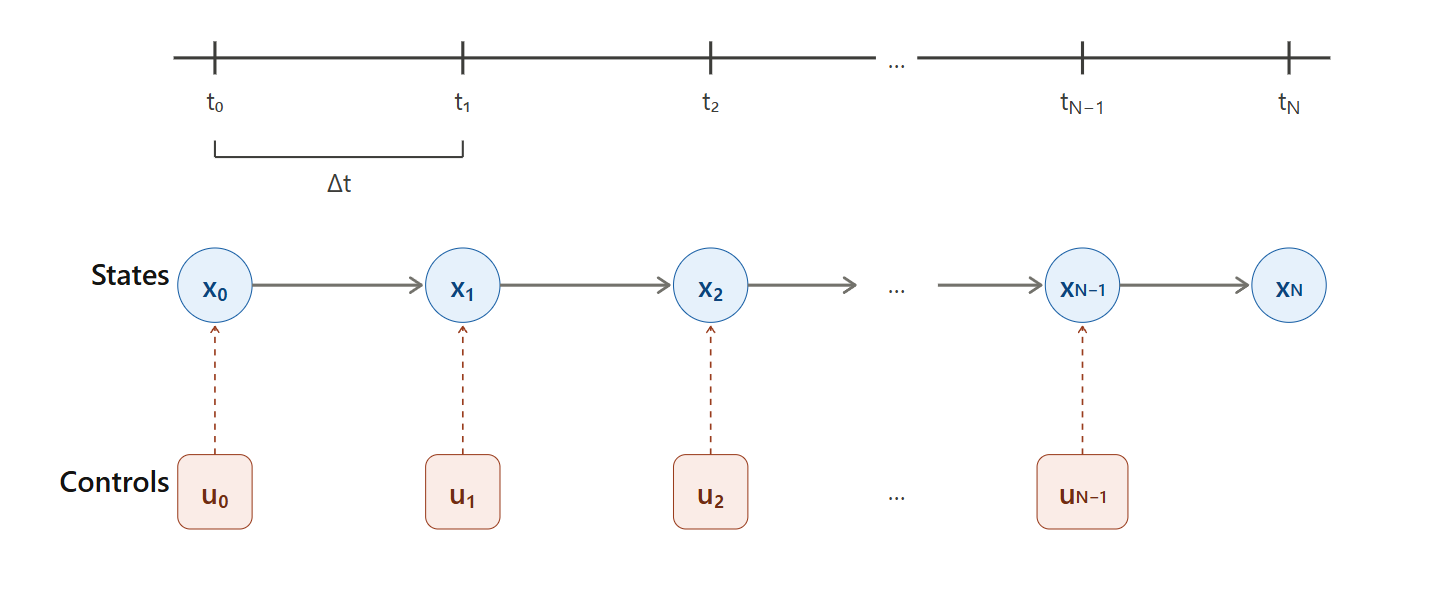 离散后状态转移遵循运动学约束:
离散后状态转移遵循运动学约束:
- 共有 个状态( 到 )
- 共有 个控制量( 到 )
- 称为 horizon(时域长度)
1.2 项目的核心数据结构
1.2.1 类型定义
本项目使用 Eigen 库进行线性代数运算,定义了两个基础类型别名:
// include/core/types.hpp
using Vector = Eigen::VectorXd; // 动态大小的列向量
using Matrix = Eigen::MatrixXd; // 动态大小的矩阵1.2.2 轨迹容器 Trajectory
轨迹是状态和控制量的有序序列,是整个项目最基本的数据结构:
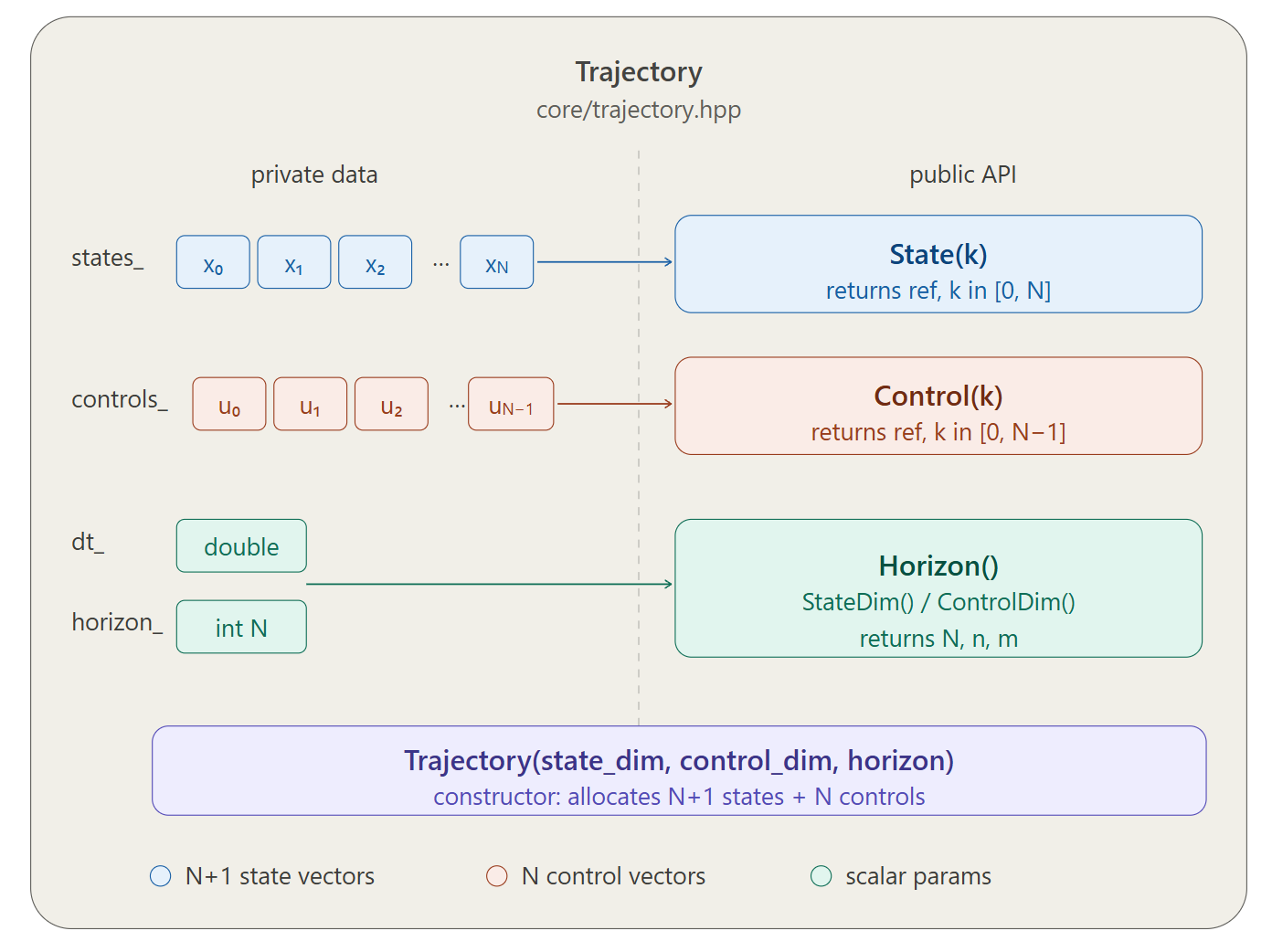
对应代码(include/core/trajectory.hpp)的核心接口:
class Trajectory {
public:
Trajectory(int state_dim, int control_dim, int horizon);
// 访问第 k 个 knot point 的状态和控制
Vector& State(int k); // k ∈ [0, N]
Vector& Control(int k); // k ∈ [0, N-1]
int Horizon() const; // 返回 N
int StateDim() const; // 状态维度 n
int ControlDim() const; // 控制维度 m
private:
std::vector<Vector> states_; // 大小 N+1
std::vector<Vector> controls_; // 大小 N
double dt_;
};
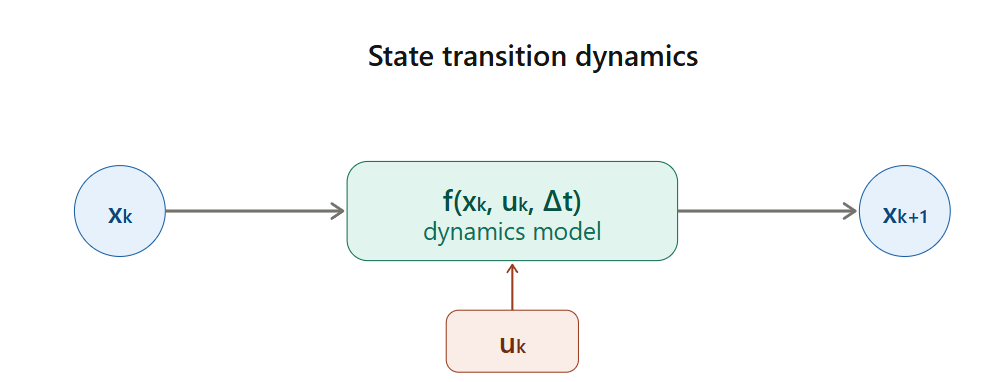
1.3 动力学模型
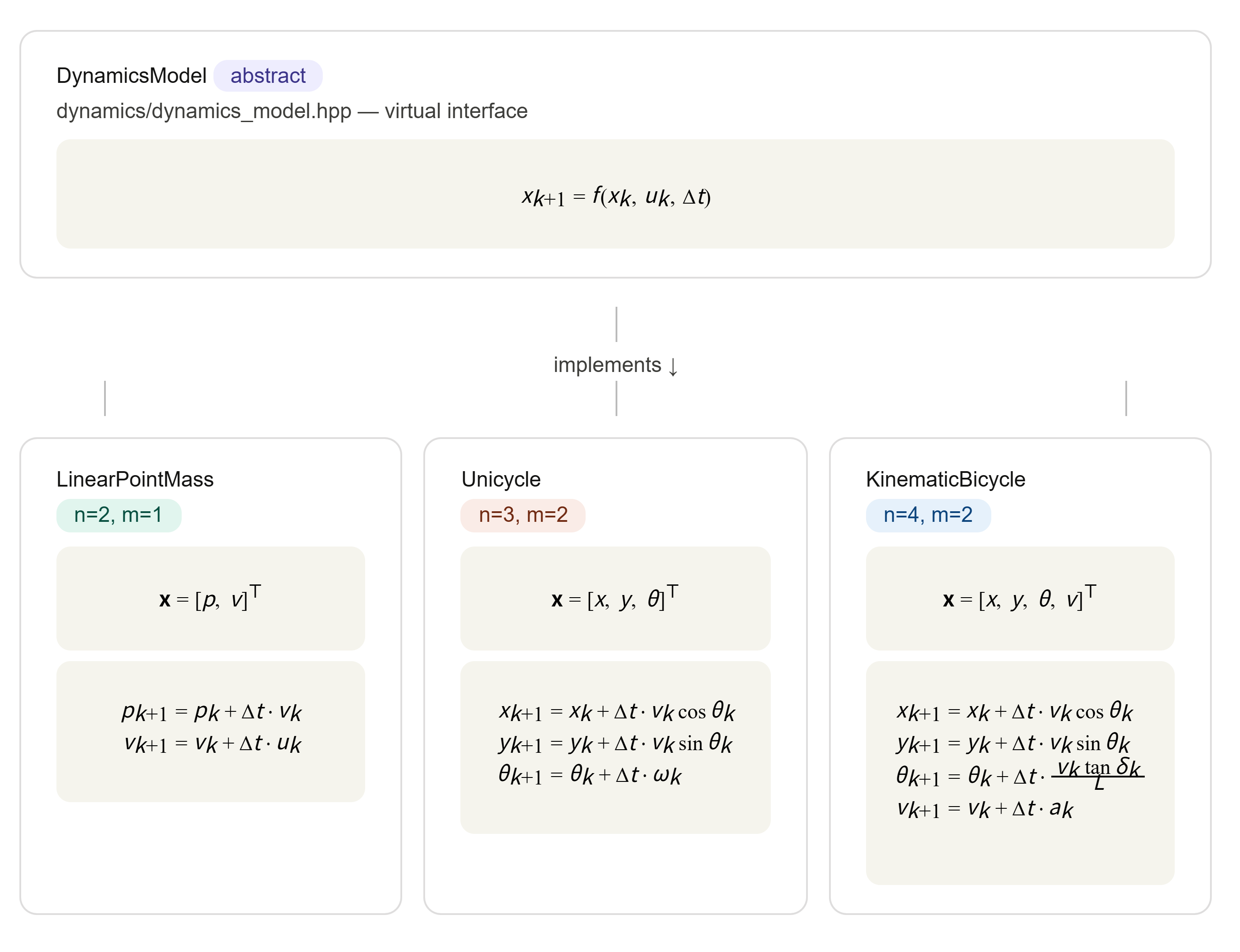
1.3.1 基础概念
动力学模型描述系统"如何从当前状态演变到下一个状态"。在离散时间下:
不同的系统有不同的 ,但接口是统一的。
1.3.2 抽象接口
// include/dynamics/dynamics_model.hpp
class DynamicsModel {
public:
virtual int StateDim() const = 0; // 状态维度 n
virtual int ControlDim() const = 0; // 控制维度 m
// 给定当前状态、控制和时间步长,返回下一个状态
virtual Vector NextState(const Vector& state,
const Vector& control,
double dt) const = 0;
};1.1.3 常见三个模型
1.3.3.1 线性点质量模型
最简单的动力学——匀加速直线运动:
其中 是位置, 是速度, 是加速度。
1.3.3.2 独轮车模型(Unicycle)
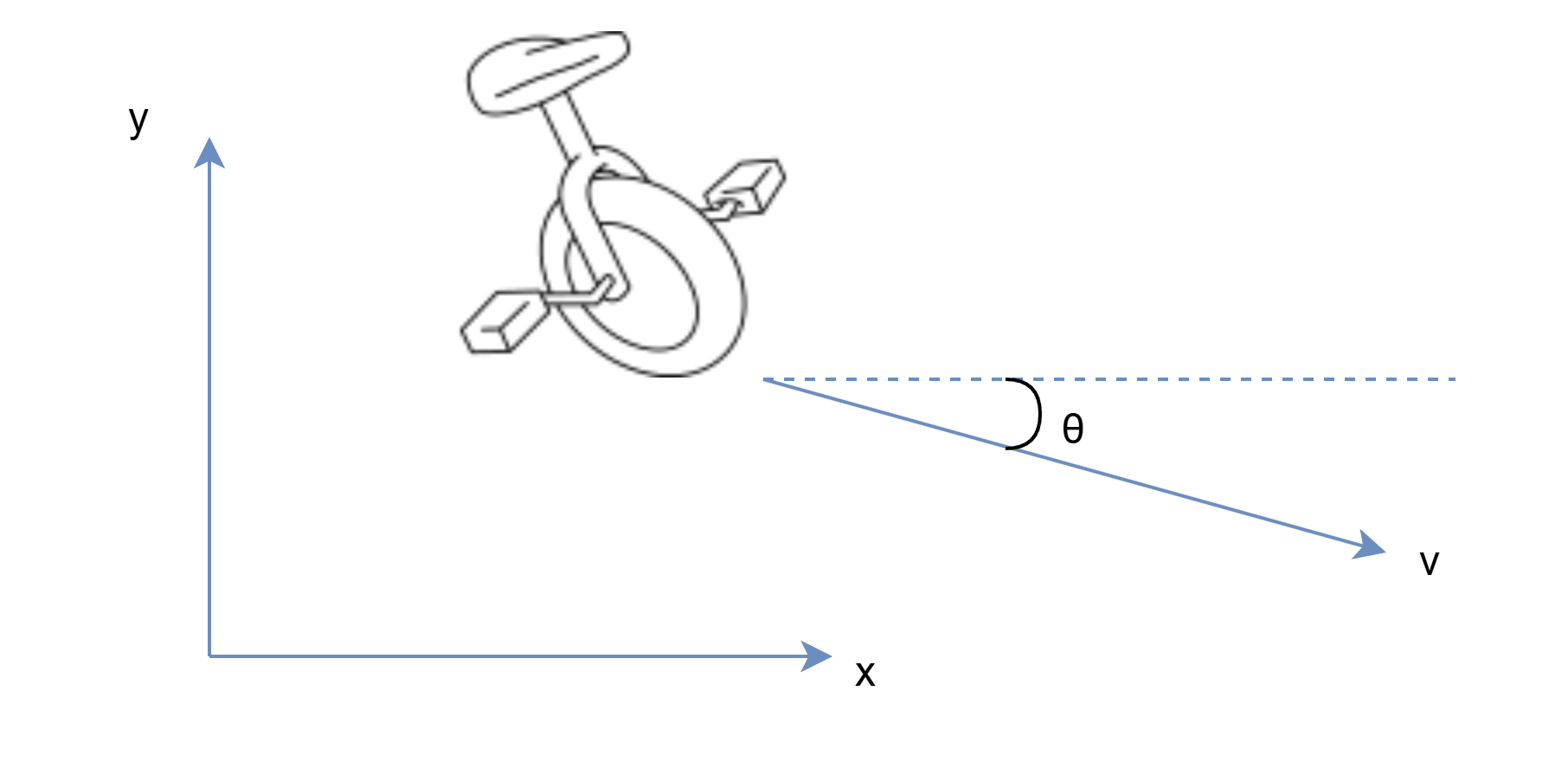
状态 ,控制 (速度和角速度):
1.3.3.3 运动学自行车模型(Kinematic Bicycle Model)
这是本项目自动驾驶场景使用的核心模型:
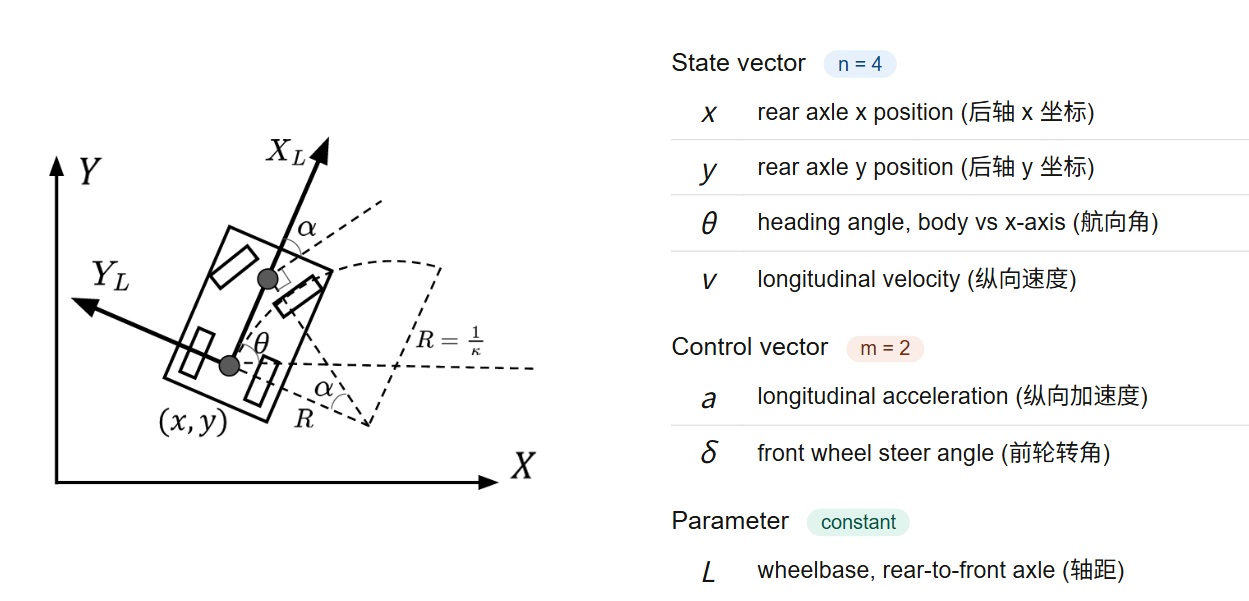
状态 ,控制 (加速度和前轮转角):
对应代码(src/dynamics/kinematic_bicycle_model.cpp):
Vector KinematicBicycleModel::NextState(const Vector& state,
const Vector& control,
double dt) const {
const double x = state(0);
const double y = state(1);
const double yaw = state(2);
const double velocity = state(3);
const double acceleration = control(0);
const double steering = control(1);
Vector next_state(StateDim());
next_state(0) = x + dt * velocity * std::cos(yaw); // x 方向位移
next_state(1) = y + dt * velocity * std::sin(yaw); // y 方向位移
next_state(2) = yaw + dt * velocity * std::tan(steering) / wheelbase_; // 航向变化
next_state(3) = velocity + dt * acceleration; // 速度变化
return next_state;
}1.4 代价函数
1.4.1 基础概念
代价函数衡量一条轨迹的"好坏"。它由两部分组成:
- 阶段代价:惩罚过程中的偏差和控制消耗
- 终端代价:惩罚最终状态离目标的距离
1.4.2 抽象接口
// include/cost/cost_function.hpp
class CostFunction {
public:
virtual int StateDim() const = 0;
virtual int ControlDim() const = 0;
// 第 k 步的阶段代价
virtual double StageCost(const Vector& state, const Vector& control) const = 0;
// 终端代价(只依赖最终状态)
virtual double TerminalCost(const Vector& state) const = 0;
};
1.4.3 二次代价函数
最常用的代价形式是带参考点的二次代价。本项目实现的 QuadraticCost 惩罚的是与参考点的偏差:
其中:
- 是状态参考点(目标状态), 是控制参考点(通常为零)
- 是状态权重矩阵, 是控制权重矩阵, 是终端权重矩阵 中对角元素越大,对应状态维度的偏差惩罚越重; 越大,控制量越保守。
对应代码(src/cost/quadratic_cost.cpp):
double QuadraticCost::StageCost(const Vector& state, const Vector& control) const {
const Vector dx = state - state_reference_; // x - x_ref
const Vector du = control - control_reference_; // u - u_ref
return 0.5 * dx.dot(Q_ * dx) + 0.5 * du.dot(R_ * du);
}
double QuadraticCost::TerminalCost(const Vector& state) const {
const Vector dx = state - state_reference_;
return 0.5 * dx.dot(Qf_ * dx);
}1.5 最优控制问题的封装
1.5.1 OptimalControlProblem 类
将动力学、代价函数、时域长度和时间步长封装在一起:
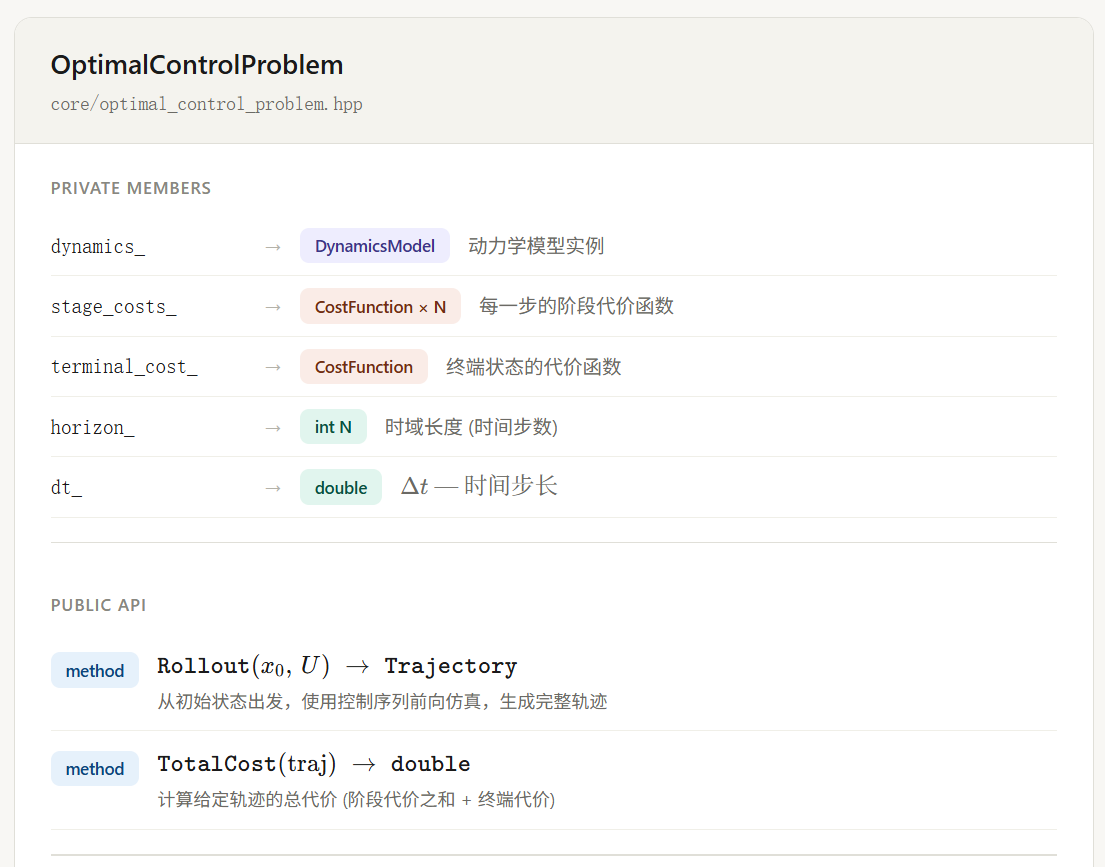
对应代码(include/problems/optimal_control_problem.hpp):
class OptimalControlProblem {
public:
OptimalControlProblem(std::shared_ptr<DynamicsModel> dynamics,
std::shared_ptr<CostFunction> cost,
int horizon, double dt);
// 前向仿真:给定初始状态和控制序列,生成完整轨迹
Trajectory Rollout(const Vector& initial_state,
const std::vector<Vector>& control_sequence) const;
// 计算轨迹总代价
double TotalCost(const Trajectory& trajectory) const;
};
1.5.2 Rollout 流程
Rollout 是轨迹优化中最基本的操作——给定初始状态和控制序列,逐步前向仿真:

对应代码(src/problems/optimal_control_problem.cpp):
Trajectory OptimalControlProblem::Rollout(const Vector& initial_state,
const std::vector<Vector>& control_sequence) const {
Trajectory trajectory(StateDim(), ControlDim(), horizon_);
trajectory.SetTimeStep(dt_);
trajectory.State(0) = initial_state; // 初始状态固定
for (int k = 0; k < horizon_; ++k) {
trajectory.Control(k) = control_sequence[k];// 填入给定的控制
trajectory.State(k + 1) = // 用动力学递推下一状态
dynamics_->NextState(trajectory.State(k), trajectory.Control(k), dt_);
}
return trajectory;
}
1.5.3 TotalCost 流程
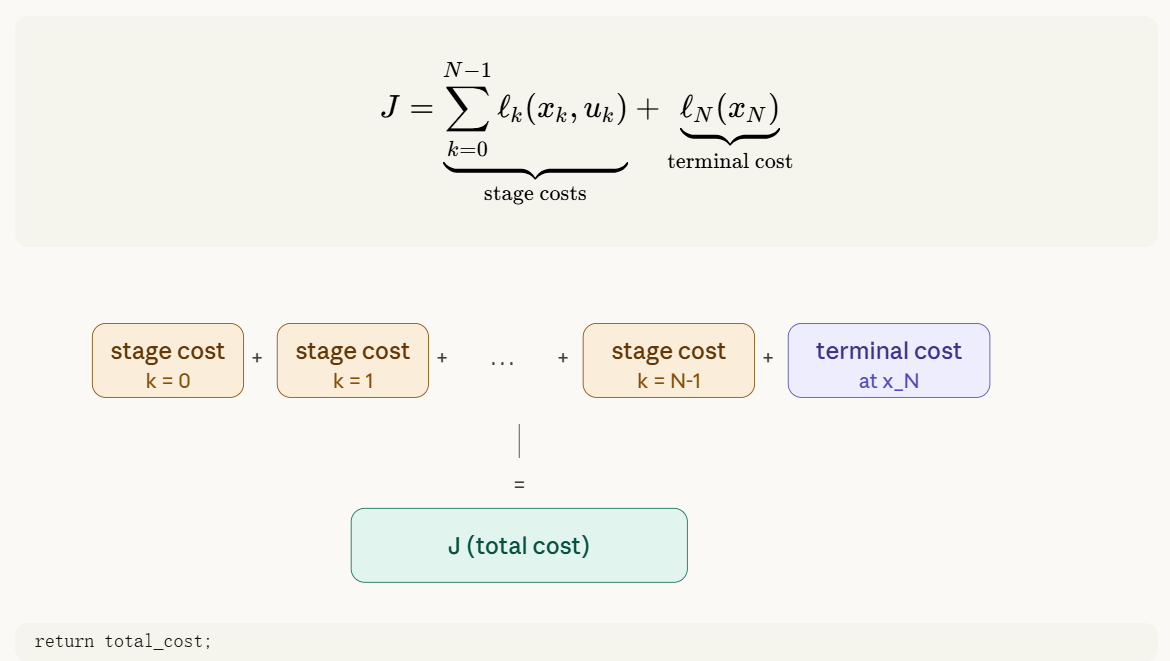
对应代码:
double OptimalControlProblem::TotalCost(const Trajectory& trajectory) const {
double total_cost = 0.0;
for (int k = 0; k < horizon_; ++k) {
total_cost += stage_costs_.at(k)->StageCost(trajectory.State(k), trajectory.Control(k));
}
total_cost += terminal_cost_->TerminalCost(trajectory.State(horizon_));
return total_cost;
}
1.6 本章小结
本章建立了轨迹优化的最小骨架,包含以下核心模块:
此时我们能做的事:
- 给定控制序列 → Rollout → 得到轨迹
- 计算轨迹的总代价
还不能做的事:
- 找到最优的控制序列 ← 这是下一章(LQR)和后续章节(iLQR)要解决的问题
评论
加入讨论
登录或注册后即可发表评论,与其他学习者交流
0 条评论
加载评论中...