
目标:将 LQR 推广到非线性系统,实现带正则化和线搜索的稳定 iLQR
3.1 从 LQR 到 iLQR:一张对比表看懂核心差异
在 Chapter 2 中,我们已经掌握了有限时域 LQR 的完整流程。iLQR(iterative Linear Quadratic Regulator)并不是一个全新的算法,而是 LQR 思路在非线性世界中的自然推广。理解 iLQR 最快的方式,就是搞清楚它和 LQR 的每一处差异是为什么出现的。
下面这张表是本章的"路线图"——后续所有内容都是在解释表中每一行差异背后的数学原理与代码实现:
| 维度 | LQR (Chapter 2) | iLQR (本章) | 差异的根源 |
|---|---|---|---|
| 动力学 | 线性 | 非线性 | 现实系统都是非线性的 |
| 已知常量,整个时域不变 | 每次迭代在当前轨迹处重新数值计算 | 非线性动力学需要局部线性化 | |
| 代价函数 | 二次 | 任意形式,用二次近似 | 一般代价不再是纯二次的 |
| 值函数形式 | 纯二次 | 带线性项 | 代价展开在非零点处会产生线性项 |
| 控制律 | 纯反馈 | 反馈 + 前馈 | 值函数的线性项 产生前馈修正 |
| 求解次数 | 一次 backward + forward | 迭代:多次 backward + forward | 局部近似只在当前轨迹附近有效 |
| 正则化 | 不需要 | 数值线性化可能导致 不正定 | |
| 线搜索 | 不需要 | 需要 backtracking line search | 大步长可能超出局部近似的有效范围 |
实现说明:本项目实现的是 iLQR(只用一阶动力学线性化 ),不是 full DDP(Differential Dynamic Programming,需要动力学二阶展开 )。所有 Jacobian 和 Hessian 均通过数值中心差分计算,不是解析导数。这简化了实现,代价是计算量较大且精度受差分步长 影响。关于与论文的完整差异清单,参见 附录 §论文步骤与代码实现对照。
3.2 核心思想:在当前轨迹处做局部 LQR
iLQR 的核心思想可以用一句话概括:在当前轨迹的每个 knot point 处,对非线性问题做局部线性/二次近似,将其转化为一个 LQR 子问题,然后迭代求解。
让我们用一个对比来直观理解。回忆 LQR 的前提条件——线性动力学和二次代价——使得整个问题天然就是一个二次优化,可以一步解析求解。但在非线性问题中:
我们无法直接套用 LQR。但如果我们"站在"当前轨迹 上,把非线性函数做 Taylor 展开,就可以得到一个局部有效的线性动力学 + 二次代价近似——这恰好就是一个 LQR 子问题!

论文(§III, Algorithm 3)中对此有精确描述:
"The key idea of DDP is that at each iteration, all nonlinear constraints and objectives are approximated using first or second order Taylor series expansions so that the approximate functions, now operating on deviations about the nominal trajectory, can be solved using discrete LQR."
注意关键词"deviations"——iLQR 优化的不是绝对状态 ,而是偏差 。这一点是理解所有后续公式的关键。
3.3 值函数的变化:为什么会出现前馈项?
这是 LQR 到 iLQR 最核心的数学差异。理解了这一点,后续所有公式都是自然推论。
3.3.1 回顾 LQR 的值函数:为什么没有线性项?
在 Chapter 2 中,值函数是纯二次形式:
注意这个表达式里没有线性项(没有 这样的项)。这不是 Taylor 展开的结果,而是 LQR 问题结构所保证的精确闭式解。我们可以用归纳法看清这一点:
- 终端:,纯二次 ✓
- 归纳步:假设 (纯二次),将其代入 Bellman 方程:
被最小化的项是 的纯二次函数(所有交叉项都是二次的,没有任何一次项)。对 求最优后代回,结果仍然是 的纯二次函数 。
根本原因:线性动力学 + 二次代价的组合,在 Bellman 递推的每一步都保持了纯二次结构。值函数的形式是精确的,不是近似。
关于参考跟踪的补充:当 时,LQR 代价 展开后确实会有线性项。但 Chapter 2 中,Riccati 递推是在调节器形式()下推导的,参考点通过控制律 在应用层处理。这不影响核心推导结构。
3.3.2 iLQR 的值函数:为什么多了线性项?
iLQR 面对的是非线性动力学 + 一般代价函数,值函数 不再是精确的二次函数,我们只能在当前 nominal 轨迹点附近做 Taylor 近似:
这里 是值函数在 nominal 点 处的梯度。在代码中,它对应 Vx;在论文(公式 (37))中对应 。
为什么 一般不为零? 让我们追根溯源——从代价函数的展开说起。
在 iLQR 中, 是当前迭代的 nominal 轨迹上的点。我们对代价函数在这个点做 Taylor 展开:
这里的 和 是代价函数在 nominal 点处的梯度。nominal 轨迹点 不是代价函数的最小值点(如果它是,我们就已经找到最优解了),所以 一般不为零。
对比:在 LQR 调节器形式中,代价 不需要"在某个点展开",因为它本身就是二次的,不存在展开点的概念。而 iLQR 对一般代价的二次近似必然依赖一个展开点,展开点不在极值处就会产生线性项。
这些线性项 沿着 backward pass 一路传递(通过 进入 ),最终在控制修正公式中产生了前馈项 。
3.3.3 直观理解
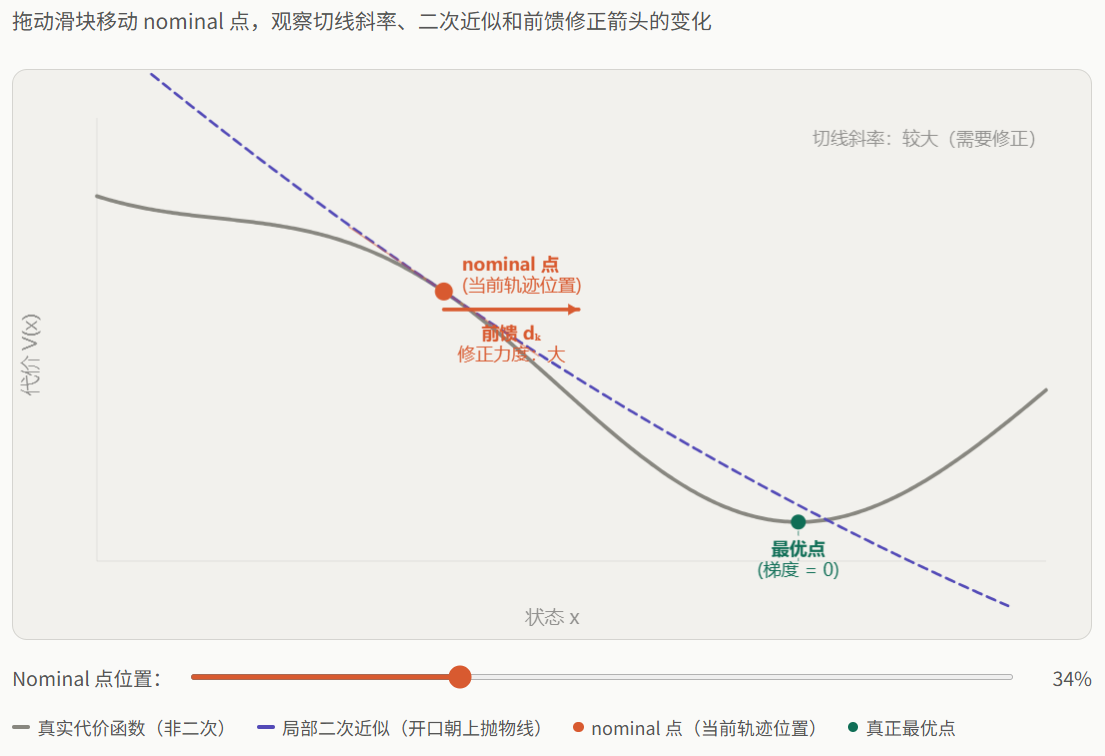
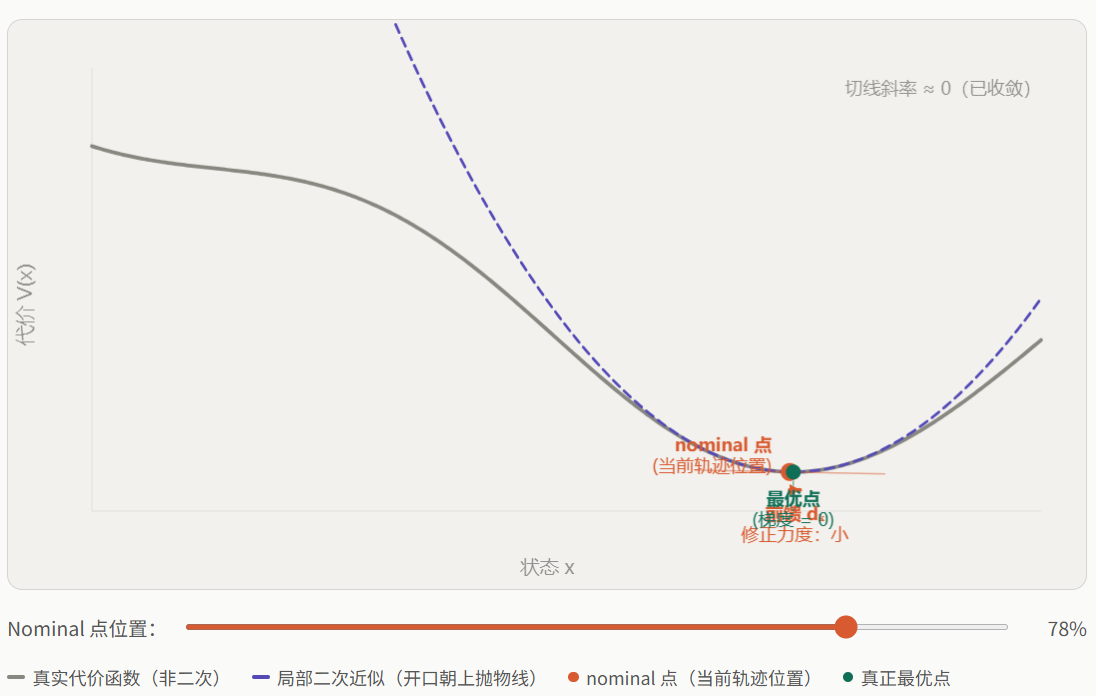
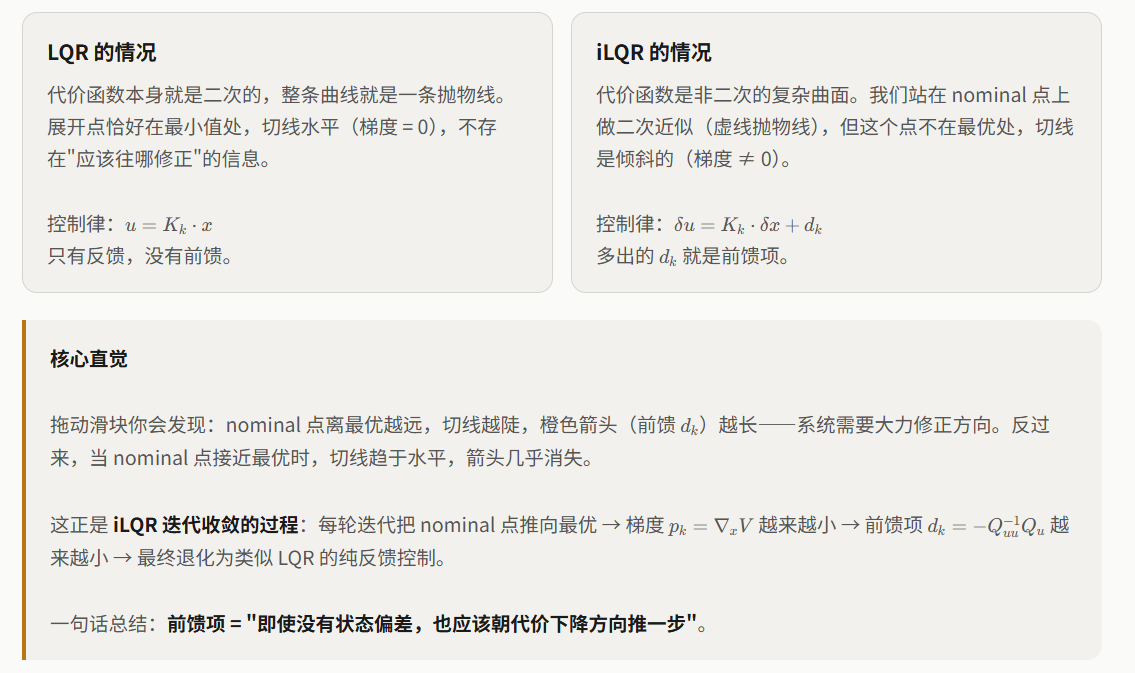 这就是为什么 iLQR 的控制律比 LQR 多了一个前馈项 :前馈项指示了从当前 nominal 点出发,即使没有状态偏差,也应该朝代价下降的方向施加修正。
这就是为什么 iLQR 的控制律比 LQR 多了一个前馈项 :前馈项指示了从当前 nominal 点出发,即使没有状态偏差,也应该朝代价下降的方向施加修正。
3.4 局部展开(Expansion)
理解了值函数差异后,我们来看 iLQR 的第一步:在当前轨迹处计算局部近似。这一步为后续的 backward pass 准备数据。
3.4.1 动力学线性化
LQR 中: 是已知常量,在整个时域上不变。 iLQR 中:在每个 knot point 处,将非线性动力学做一阶 Taylor 展开(对应论文 §III.A 中 , 的定义):
其中 Jacobian 矩阵在每次迭代时重新计算:
本项目使用中心差分数值计算 Jacobian(论文中写的是解析形式,这是工程化简化):
对应代码(src/ilqr/ilqr_solver.cpp):
Matrix ILQRSolver::DynamicsJacobianState(const Vector& state, const Vector& control) const {
const double eps = options_.derivative_epsilon; // 典型值: 1e-4
Matrix jac = Matrix::Zero(problem_.StateDim(), problem_.StateDim());
for (int i = 0; i < problem_.StateDim(); ++i) {
Vector x_plus = state;
Vector x_minus = state;
x_plus(i) += eps;
x_minus(i) -= eps;
const Vector f_plus = problem_.Dynamics().NextState(x_plus, control, problem_.TimeStep());
const Vector f_minus = problem_.Dynamics().NextState(x_minus, control, problem_.TimeStep());
jac.col(i) = (f_plus - f_minus) / (2.0 * eps); // 中心差分
}
return jac;
}
与 LQR 的对比:LQR 中 problem_.A 直接取出来就能用;iLQR 中每个 knot point 都要算一遍 Jacobian,而且每次外层迭代轨迹变了,Jacobian 也要重算。这就是 iLQR 计算量更大的原因之一。
3.4.2 代价二次化
类似地,对代价函数也需要做局部展开。 LQR 中:代价的二阶展开系数就是 本身,已知且不变。 iLQR 中:代价函数可以是任意形式,需要在每个 knot point 上数值计算梯度和 Hessian:
注意 这两个一阶项——在 LQR 中(当参考点为零时)它们为零,正是它们的存在导致了 iLQR 中的前馈项。
代码中封装为 CostExpansion 结构:
struct CostExpansion {
Vector lx; // ∂ℓ/∂x (n×1) ← LQR中为零!
Vector lu; // ∂ℓ/∂u (m×1) ← LQR中为零!
Matrix lxx; // ∂²ℓ/∂x² (n×n) ← LQR中对应 Q
Matrix lux; // ∂²ℓ/∂u∂x (m×n) ← LQR中为零
Matrix luu; // ∂²ℓ/∂u² (m×m) ← LQR中对应 R
};
3.4.3 展开的完整流程
对每个 knot point ,计算动力学 Jacobian 和代价展开:
void ILQRSolver::UpdateExpansions(const Trajectory& trajectory) {
for (int k = 0; k < problem_.Horizon(); ++k) {
A_[k] = DynamicsJacobianState(trajectory.State(k), trajectory.Control(k));
B_[k] = DynamicsJacobianControl(trajectory.State(k), trajectory.Control(k));
stage_expansions_[k] = StageCostExpansion(k, trajectory.State(k), trajectory.Control(k));
}
}
与 LQR 的对比:LQR 根本没有"展开"这一步,因为 本来就是已知的。iLQR 的这一步相当于"把非线性问题就地改造成 LQR 子问题的输入"。
3.5 Backward Pass
Backward pass 是 iLQR 的核心。本节会从"backward pass 要解决什么问题"讲起,逐步引出 Action-Value 函数、Q-value 展开、正则化等概念,最后落地到代码。

3.5.1 Backward Pass 要解决什么问题?
在 §3.4 中,我们已经在当前轨迹的每个 knot point 处算好了局部近似数据( 和代价导数)。现在的问题是:如何利用这些数据,算出每一步的最优控制修正 ?
回忆 Chapter 2 中 LQR 的思路——动态规划:
- 先知道终端的代价()
- 从终端往前递推:在第 步,假设"从 步往后走的最优代价"已经知道了(),那第 步的最优控制就是"选一个 ,使得当前步代价 + 后续最优代价之和最小"
- 这就是 Bellman 方程,递推求解得到每一步的最优增益
iLQR 的 backward pass 做的是完全相同的事情,只是因为问题是非线性的,具体公式更复杂一些。
3.5.2 什么是 Action-Value 函数?
为了找到第 步的最优控制,我们需要一个工具来衡量"在第 步选择某个控制 有多好"。这就是 Action-Value 函数(也叫 Q 函数)。
命名来源:"Action"指的就是"动作/控制","Value"指的是"代价"。所以 Action-Value 函数 = "执行某个动作后得到的总代价"。它在强化学习中也被称为 Q 函数(Q-function),这里用的 和代价矩阵 (状态权重)是完全不同的概念,只是碰巧用了同一个字母。
定义:
直观理解:
时间步: k k+1 k+2 ... N
│ │ │ │
▼ ▼ ▼ ▼
代价: ℓ_k(x,u) ℓ_{k+1} ℓ_{k+2} ... ℓ_N(x_N)
├──────┤ ├──────────────────────────────┤
当前步代价 后续最优代价 V_{k+1}
└─────────────────────────────────────────┘
Q_k(x_k, u_k) = 两部分之和
有了 ,寻找最优控制就变成了一个简单的优化问题:
也就是说:对 关于 求最小值,就得到了最优控制和最优值函数。
3.5.3 在 LQR 中回顾 Action-Value 函数
为了建立直觉,先看 LQR 中 Action-Value 函数长什么样。
在 Chapter 2 中,LQR 的值函数是 ,动力学是 ,代入定义:
这是 的纯二次函数。对 求导令其为零:
解出:
这就是 Chapter 2 中的 Riccati 公式!可以看到,LQR 的 Riccati 递推本质上就是在对 Action-Value 函数求最优。只是 Chapter 2 中没有显式引入"Action-Value"这个名字。
3.5.4 从 LQR 到 iLQR:Action-Value 的 Taylor 展开
在 iLQR 中, 和 都是非线性的, 不再是 的二次函数,无法直接对 解析求最优。 解决办法:在当前 nominal 点 处对 做二阶 Taylor 展开,用一个二次函数来近似它,然后对这个二次近似求最优。 展开后的结果(对应论文公式 (40)):
这里 是一阶项(梯度), 是二阶项(Hessian 的各个块)。
符号澄清:这里的 中的大写 代表 Action-Value 函数 的导数,不是代价矩阵。本章遵循论文的符号惯例,用下标表示对哪个变量求导。
3.5.5 Q-value 展开的具体公式
展开 并利用 §3.4 中准备好的展开数据,可以逐项写出(对应论文公式 (41)-(45),忽略约束项):
符号对照表(建议在阅读后续公式时随时回来查):
| 符号 | 含义 | 维度 | 代码变量 | LQR 中的对应 |
|---|---|---|---|---|
| 阶段代价对状态的梯度 | expansion.lx | 零(调节器形式) | ||
| 阶段代价对控制的梯度 | expansion.lu | 零 | ||
| 阶段代价对状态的 Hessian | expansion.lxx | (状态代价矩阵) | ||
| 阶段代价的交叉 Hessian | expansion.lux | 零 | ||
| 阶段代价对控制的 Hessian | expansion.luu | (控制代价矩阵) | ||
| 动力学对状态的 Jacobian | A_[k] | (状态转移矩阵,固定) | ||
| 动力学对控制的 Jacobian | B_[k] | (控制输入矩阵,固定) | ||
| 或 | 第 步值函数梯度 | Vx | 零(LQR 值函数无线性项) | |
| 或 | 第 步值函数 Hessian | Vxx | (Riccati 矩阵) |
一阶项(Action-Value 函数的梯度):
直观理解: 告诉我们"当前状态往哪个方向偏一点,总代价下降最快"; 告诉我们"控制往哪个方向调一点,总代价下降最快"。每一项都有两个来源——当前步代价的梯度()和后续代价通过动力学传回来的梯度()。
二阶项(Action-Value 函数的 Hessian):
直观理解: 衡量的是"控制变化对总代价的二阶影响"——它决定了最优控制附近代价曲面的"曲率"。 正定意味着代价曲面是碗状的(有唯一最小值),可以求最优。
对比要点:二阶项 的结构与 LQR 完全相同,只是把固定已知的 换成了数值计算的 。真正新增的是一阶项 ——正是 导致了后面的前馈项 。
3.5.6 求解最优控制修正
现在,Action-Value 函数已经被近似为 的二次函数了。求最优控制修正量只需对 求导令其为零:
解出:
即(对应论文公式 (46)):
这个公式就是 iLQR 的控制律。下面逐一解释这三个术语。
什么是控制律?
控制律(control law) 是一个从"当前观测"到"应该施加什么控制"的映射规则。给定当前状态,控制律告诉你该做什么。
- LQR 的控制律: —— 观测到状态 ,乘以矩阵 ,得到控制 。
- iLQR 的控制律: —— 观测到状态偏差 ,乘以 再加上 ,得到控制修正 。 之所以叫"律",是因为一旦 backward pass 算出了 和 ,在 forward pass 中就机械地按这个规则执行即可,不需要再做任何优化计算。
什么是反馈项?
称为反馈项(feedback term)。 "反馈"的意思是:这一项依赖于当前的实际状态。它观测到"实际轨迹和 nominal 轨迹之间的偏差 ",然后据此调整控制。偏差越大,修正越大;没有偏差,这一项就是零。
生活中的类比:开车时方向盘的微调。你眼睛(传感器)看到车偏离了车道中线(状态偏差),于是手(控制器)转方向盘纠正。这就是反馈——先观测偏差,再做出响应。
称为反馈增益(feedback gain),它决定了"偏差有多大时,修正有多大"——增益越大,对偏差的响应越激烈。
什么是前馈项?
称为前馈项(feedforward term)。
"前馈"的意思是:这一项不依赖当前状态。无论实际状态偏差 是什么(哪怕为零), 都会施加一个固定的控制修正。
生活中的类比:开车时你知道前方有一个弯道,于是提前转方向盘。这不是因为你看到车偏了(偏差为零),而是因为你预判了需要转弯。这就是前馈——不等偏差发生,主动施加控制。
在 iLQR 中, 的方向由 (Action-Value 函数关于控制的梯度)决定。 告诉我们"当前控制应该朝哪个方向调整,总代价才能下降"——这就是 所编码的"预判"。
为什么 LQR 没有前馈项?
在 LQR(调节器形式)中,(见 §3.3.1 的分析),所以 。物理上,LQR 的代价函数以参考点为中心、完美对称,不存在"应该主动往某个方向调"的预判——只要把偏差纠正回零就够了。
而 iLQR 中,当前 nominal 轨迹不在最优点上,,代价在某个方向上还有下降空间。前馈项 就是在说:"除了纠正偏差之外,还应该朝这个方向额外推一把。"
| 项 | 公式 | 名称 | 是否依赖状态 | 物理含义 |
|---|---|---|---|---|
| 反馈项 | 是 | 观测偏差,纠正回 nominal | ||
| 前馈项 | 否 | 无论有无偏差,主动朝更优方向修正 |
与 LQR 的对比:
- LQR 中 ,所以 ——控制律只有反馈项 。
- iLQR 中 ,所以多了前馈项 ,这是 §3.3 分析的线性项的直接后果。
- 的计算公式与 LQR 形式相同,只是用 替换了 LQR 中的 。
论文在公式 (46) 之后的评述印证了这一点:
"Take a quick moment to note that this is almost exactly the same as (30), except we have now added some regularization... and now have a feedforward term, which results from the linear terms in the expansion."
3.5.7 正则化:为什么需要,做了什么
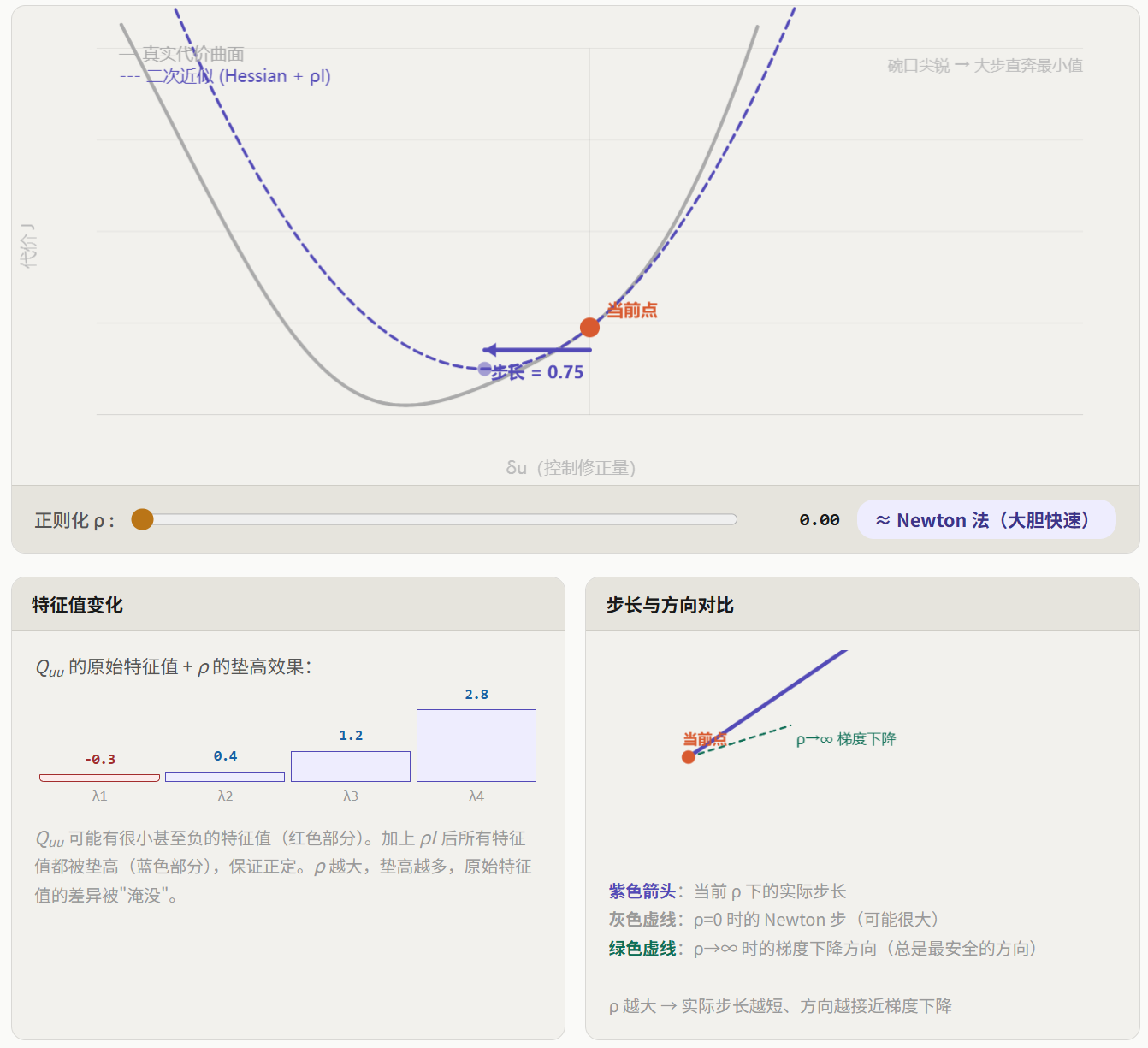
上面的公式需要对 求逆。这在 LQR 中不是问题( 天然正定),但在 iLQR 中可能出大问题。
为什么 可能不正定?
。在 iLQR 中:
- 是通过中心差分数值计算的,可能有误差;
- (即
Vxx)是上一步递推的结果,可能累积了近似误差; - 如果当前轨迹离最优解很远,局部二次近似本身就可能不准确。
当 不正定时,代价曲面不是碗状的(可能是鞍面或平面),求出来的"最优方向"可能实际上是代价增大的方向——这会导致算法发散。
正则化的做法:给 加一个正定对角矩阵:
其中 是正则化参数。加了 后, 的所有特征值都增大了 ,只要 足够大,就能保证正定。
实际求解时使用正则化后的 :
正则化的物理含义:
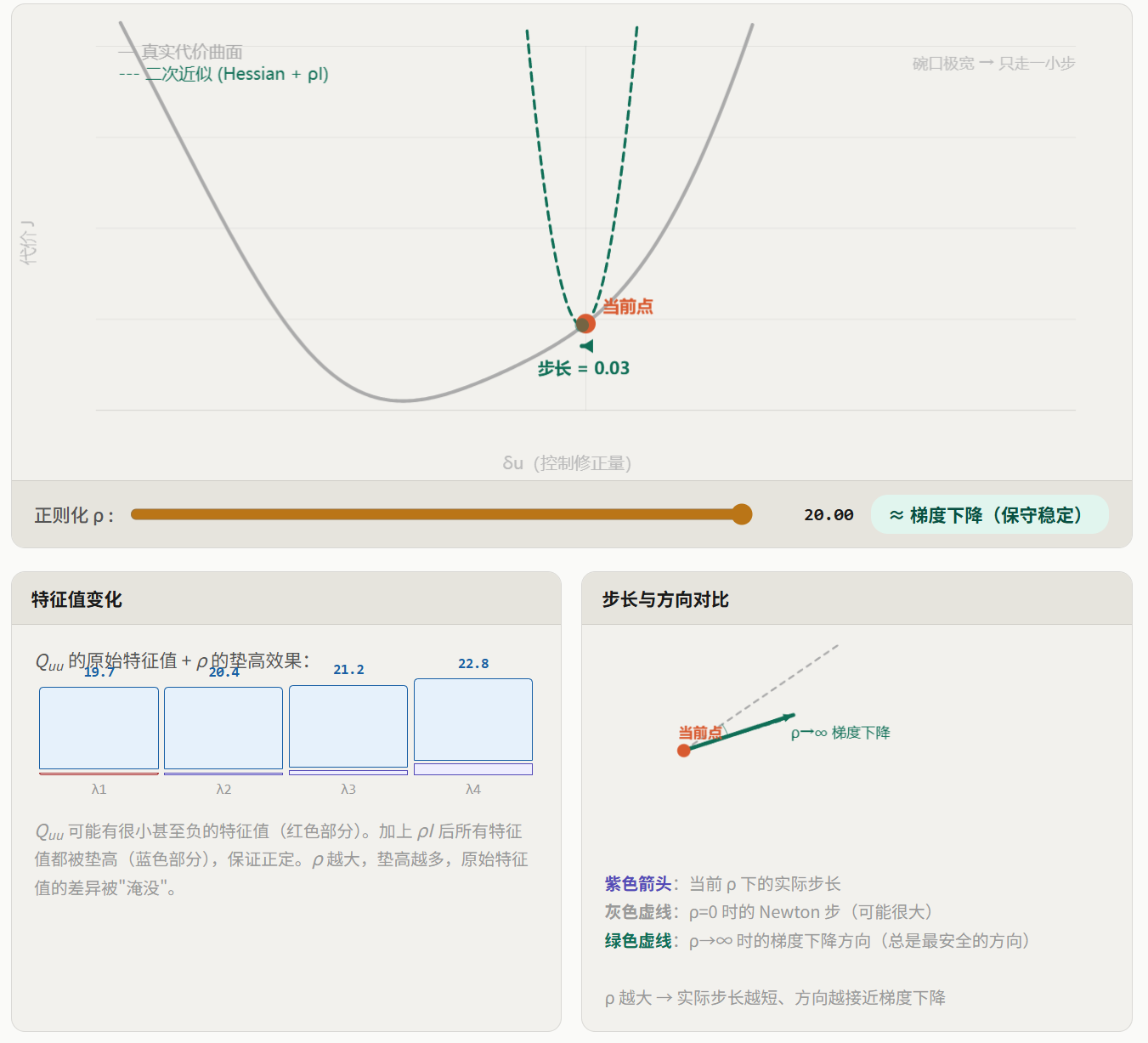
论文(§III.B.2)的原话:
"Increasing the regularization term effectively makes the partial Hessian... more like the identity matrix, effectively 'steering' the Newton (or Gauss-Newton) step direction towards the more naive gradient descent direction, which tends to be more reliable when the current iterate is far from the local optimum."
代码中的实现:用 Cholesky 分解(LLT)来同时完成"检测正定性"和"求解":
const Matrix Quu_reg =
Quu + regularization * Matrix::Identity(problem_.ControlDim(), problem_.ControlDim());
Eigen::LLT<Matrix> llt(Quu_reg);
if (llt.info() != Eigen::Success) {
return false; // Cholesky 失败 → Q_uu^reg 仍然不正定 → 需要进一步增大 ρ
}
// Cholesky 成功 → 用 LLT 高效求解线性方程组(比显式求逆更稳定)
feedback_gains_[k] = -llt.solve(Qux); // K = -(Q_uu+ρI)⁻¹ Q_ux
feedforward_terms_[k] = -llt.solve(Qu); // d = -(Q_uu+ρI)⁻¹ Q_uLLT vs 显式求逆:代码中不会真的计算 。Cholesky 分解把矩阵分解为 ,然后通过前代/回代求解线性方程组 。这比求逆更快、数值更稳定。
3.5.8 更新值函数:为下一步递推做准备
为什么需要这一步?
回顾 backward pass 的递推结构:要算第 步的 Q-value 展开(§3.5.5),需要用到第 步值函数的 (梯度)和 (Hessian)。所以在第 步算完 之后,必须把第 步的值函数信息算出来,作为第 步的输入。
递推的数据流:
k+1 步的值函数 (p', P')
│
▼
第 k 步: 组装 Q-value 展开 → 求 K_k, d_k → 算出第 k 步的值函数 (p_k, P_k)
│
▼
第 k-1 步: 用 p_k, P_k 作为 p', P' 继续递推...
这就引出了核心问题:第 步的值函数是什么?怎么算?
值函数和 的关系
在 §3.3.2 中我们说过,iLQR 的值函数用 Taylor 展开近似:
这里 是常数项(在第 步确定后就固定了), 是梯度, 是 Hessian。
关键理解: 和 就是值函数的完整"身份证"。在 backward pass 递推中,我们不需要知道值函数的精确形式——只需要知道它在 nominal 点附近的二阶 Taylor 展开系数就够了。因为下一步递推(§3.5.5)也只用到这两个量。
所以"更新值函数"实际上就是"算出 和 这两个系数"。
对比 LQR:在 Chapter 2 中,,值函数完全由 一个矩阵表示(没有线性项)。LQR 的"更新值函数"就是 Riccati 递推 。
怎么算 和 ?
思路很自然:值函数 = Action-Value 在最优控制处的值:
把 代入 §3.5.4 的 Action-Value 二次展开式,整理后得到 的二次函数,其中的二次项系数就是 ,线性项系数就是 。
结果(对应论文公式 (47)-(49)):
可以这样理解每一项的来源:
- (值函数的 Hessian,即曲率): 是不含控制时的曲率,后三项是最优控制耦合进来的额外曲率。
- (值函数的梯度,即斜率): 是不含控制时的梯度,后三项是最优控制耦合进来的梯度修正。
- (期望代价减少量):这不是值函数本身的一部分,而是一个副产品——它记录了"通过施加前馈修正 ,预期能减少多少代价"。这个量将在 forward pass 的线搜索中使用(§3.6.3)。
一个完整例子
假设我们在第 步:
已知 要算
│ │
▼ ▼
┌──────────────────────────────────┐ ┌──────────────────────────┐
│ 输入: │ │ 输出: │
│ p' = p₄ (第4步值函数梯度) │ │ p₃ (第3步值函数梯度) │
│ P' = P₄ (第4步值函数Hessian) │ │ P₃ (第3步值函数Hessian)│
│ A₃, B₃ (动力学 Jacobian) │ │ K₃ (反馈增益) │
│ ℓ_x, ℓ_u, ℓ_{xx}... (代价展开) │ │ d₃ (前馈项) │
└──────────────────────────────────┘ │ ΔV₃ (期望下降量) │
│ └──────────────────────────┘
▼ │
§3.5.5 组装 Q-value 展开 │
│ │
▼ │
§3.5.6 求 K₃, d₃ │
│ │
▼ │
代入公式 → 得到 p₃, P₃, ΔV₃ ─────────────────────┘
│
▼
p₃, P₃ 传递给第 k=2 步作为 p', P' 使用
符号对照表(Backward Pass 输出):
| 符号 | 含义 | 代码变量 | LQR 对应 |
|---|---|---|---|
| 第 步值函数 Hessian | Vxx | Riccati 矩阵 | |
| 第 步值函数梯度 | Vx | 不存在(LQR 无此项) | |
| 反馈增益矩阵 | feedback_gains_[k] | LQR 反馈增益 | |
| 前馈修正向量 | feedforward_terms_[k] | 不存在(LQR 无此项) | |
| 期望代价减少量 | 累加到 expected_linear, expected_quadratic | 不存在(LQR 不做线搜索) |
与 LQR 的对比:
- LQR 中,"更新值函数"就是 Riccati 递推 ——只需要更新一个矩阵 。
- iLQR 中,需要同时更新 (Hessian)和 (梯度)——因为值函数多了线性项。
- 是 iLQR 独有的副产品,LQR 不迭代、不做线搜索,所以不需要。
3.5.9 完整 Backward Pass 代码
下面的代码实现了上述所有步骤。建议与 Chapter 2 中 LQR Solve() 函数的 Riccati 递推对比阅读:
bool ILQRSolver::BackwardPass(const Trajectory& trajectory,
double regularization,
double* expected_linear,
double* expected_quadratic) {
// ═══ Step 1: 终端值函数初始化 ═══
// LQR: 只需 P_N = Q_f
// iLQR: 同时需要梯度 p_N 和 Hessian P_N
const auto [terminal_gradient, terminal_hessian] =
TerminalCostExpansion(trajectory.State(problem_.Horizon()));
Vector Vx = terminal_gradient; // p_N: 值函数梯度
Matrix Vxx = terminal_hessian; // P_N: 值函数 Hessian
*expected_linear = 0.0;
*expected_quadratic = 0.0;
// ═══ Step 2: 从 k=N-1 递推到 k=0 ═══
for (int k = problem_.Horizon() - 1; k >= 0; --k) {
const auto& expansion = stage_expansions_[k];
const Matrix& A = A_[k];
const Matrix& B = B_[k];
// ── Step 2a: Q-value 展开 (§3.5.5, 论文公式 (41)-(45)) ──
const Vector Qx = expansion.lx + A.transpose() * Vx;
const Vector Qu = expansion.lu + B.transpose() * Vx;
const Matrix Qxx = expansion.lxx + A.transpose() * Vxx * A;
const Matrix Qux = expansion.lux + B.transpose() * Vxx * A;
const Matrix Quu = expansion.luu + B.transpose() * Vxx * B;
// ── Step 2b: 正则化 + Cholesky 分解 (§3.5.7) ──
const Matrix Quu_reg =
Quu + regularization * Matrix::Identity(problem_.ControlDim(), problem_.ControlDim());
Eigen::LLT<Matrix> llt(Quu_reg);
if (llt.info() != Eigen::Success) {
return false; // Q_uu^reg 不正定 → 外层会增大 ρ 后重试
}
// ── Step 2c: 求增益 (§3.5.6, 论文公式 (46)) ──
feedback_gains_[k] = -llt.solve(Qux); // K_k = -(Q_uu+ρI)⁻¹ Q_ux
feedforward_terms_[k] = -llt.solve(Qu); // d_k = -(Q_uu+ρI)⁻¹ Q_u
// ── Step 2d: 累计期望代价减少量 (§3.5.8, 论文公式 (49)) ──
*expected_linear += Qu.dot(feedforward_terms_[k]);
*expected_quadratic += 0.5 * feedforward_terms_[k].dot(Quu * feedforward_terms_[k]);
// ── Step 2e: 更新值函数 (§3.5.8, 论文公式 (47)-(48)) ──
Vx = Qx + feedback_gains_[k].transpose() * Quu * feedforward_terms_[k]
+ feedback_gains_[k].transpose() * Qu
+ Qux.transpose() * feedforward_terms_[k];
Vxx = Qxx + feedback_gains_[k].transpose() * Quu * feedback_gains_[k]
+ feedback_gains_[k].transpose() * Qux
+ Qux.transpose() * feedback_gains_[k];
Vxx = 0.5 * (Vxx + Vxx.transpose()); // 对称化,防止数值误差累积
}
return true;
}3.6 Forward Pass
3.6.1 Forward Pass 的角色:输入、输出、目标
Backward pass 算出了每一步的控制策略 。但这只是一组"建议"——是基于局部近似推导出来的。Forward pass 的任务是:用这些建议实际仿真出一条新轨迹,并验证它确实比旧轨迹更好。
Forward Pass 的输入和输出:
输入:
├─ 当前 nominal 轨迹: {x₀, x₁, ..., x_N} 和 {u₀, u₁, ..., u_{N-1}}
├─ Backward pass 的结果: {K₀, K₁, ..., K_{N-1}} 和 {d₀, d₁, ..., d_{N-1}}
├─ 期望代价下降量: ΔV₁ (一阶), ΔV₂ (二阶) ← backward pass 的副产品
└─ 当前轨迹的总代价: J_old
输出 (成功时):
├─ 更好的新轨迹: {x̄₀, x̄₁, ..., x̄_N} 和 {ū₀, ū₁, ..., ū_{N-1}}
├─ 新轨迹的代价: J_new < J_old
└─ 实际使用的步长: α
输出 (失败时):
└─ 返回 false,外层会增大正则化后重试
在 LQR 中,forward simulate 非常简单——直接用 仿真就行,结果一定是最优的。iLQR 的 forward pass 之所以复杂得多,是因为需要线搜索(line search)来控制步长。接下来我们从"什么是线搜索"开始讲。
3.6.2 什么是线搜索?
线搜索是一种通用的优化技巧,核心思想非常简单:知道了该往哪个方向走(方向),但不确定该走多远(步长),所以从大步长开始试,如果不行就缩小步长重试。
用登山来类比:
你站在山坡上,想找到山谷最低点:
1. 你算出了"往北偏西 30° 走"是下降最快的方向 ← backward pass 的工作
2. 但你不知道该走 100 米还是 10 米:
- 走 100 米?太远了,可能翻过山谷走到对面山坡上去(代价反而增大)
- 走 10 米?安全,但很慢
1. 线搜索的做法:
先试走 100 米 (α=1)
├─ 到了更低的地方? → 接受!
└─ 没有更低? → 退回来,试走 50 米 (α=0.5)
├─ 到了更低的地方? → 接受!
└─ 没有更低? → 退回来,试走 25 米 (α=0.25)
└─ ... 直到找到一个可接受的步长
在 iLQR 中:
- "方向" = 前馈项 (backward pass 告诉我们控制该往哪个方向调)
- "步长" = (线搜索参数,缩放前馈项的大小)
- "更低的地方" = 新轨迹的总代价
3.6.3 为什么 LQR 不需要线搜索而 iLQR 需要?
LQR 中,整个问题(动力学 + 代价)都是精确的线性-二次结构。Backward pass 基于这个精确结构算出的 就是全局最优解——用它仿真出来的轨迹保证是最优的,不存在"步子太大"的问题。
iLQR 中,backward pass 是基于局部 Taylor 近似算出 和 的。这些近似只在当前轨迹的邻域内有效。如果新轨迹离旧轨迹太远,近似就不准了。线搜索通过缩小 来保证新轨迹落在近似有效的范围内。
3.6.4 闭环 Rollout:怎么用 仿真新轨迹
给定步长 ,forward pass 按以下规则从头到尾仿真一条新轨迹(对应论文公式 (50)-(53),Algorithm 2):
对每个 :
注意 只缩放前馈项 ,不缩放反馈项 。这是因为两者的角色不同:
- 反馈项 :纠正新轨迹与旧轨迹之间已经产生的偏差。这个偏差已经是事实了,必须全力纠正,缩放反馈反而会让轨迹发散。
- 前馈项 :主动将控制往"更优"方向推。这个"方向"是基于近似算出来的,步子太大可能出错,所以需要 控制。
让我们用一个具体的 3 步例子走一遍:
给定: 旧轨迹 {x₀,x₁,x₂,x₃}, {u₀,u₁,u₂} 和步长 α = 0.5
k=0:
x̄₀ = x₀ (起点固定)
δx₀ = x̄₀ - x₀ = 0 (第一步偏差为零)
ū₀ = u₀ + 0.5·d₀ + K₀·0 = u₀ + 0.5·d₀ (只有半步前馈)
x̄₁ = f(x̄₀, ū₀) (非线性传播)
k=1:
δx₁ = x̄₁ - x₁ (由于 ū₀ 不同,x̄₁ ≠ x₁,偏差不为零了)
ū₁ = u₁ + 0.5·d₁ + K₁·δx₁ (前馈 + 反馈都有)
x̄₂ = f(x̄₁, ū₁)
k=2:
δx₂ = x̄₂ - x₂
ū₂ = u₂ + 0.5·d₂ + K₂·δx₂
x̄₃ = f(x̄₂, ū₂)
结果: 候选轨迹 {x̄₀,x̄₁,x̄₂,x̄₃}, {ū₀,ū₁,ū₂}
→ 计算候选轨迹的总代价 J_new
→ 和旧代价 J_old 比较
3.6.5 如何判断新轨迹是否"够好"?
仿真出候选轨迹后,需要判断它是否值得接受。最简单的办法是"代价下降了就接受",但 iLQR 用了一个更精细的标准——比较实际下降量与预期下降量的比值(对应论文公式 (54)-(55))。
什么是期望下降量?
在 backward pass 中,我们算出了每一步的 (§3.5.8)。这是基于二次近似预测的代价减少量——"如果近似完全准确,施加前馈修正 应该能减少这么多代价"。
累加所有时间步并考虑步长 后,总的期望下降量为:
直观理解: 越小,期望下降量越小(步子小,进展小); 时是 backward pass 预测的最大进展。
实际下降量 vs 期望下降量
这个比值 衡量了"二次近似有多准":
| 的值 | 含义 | 说明 |
|---|---|---|
| 实际下降 预期下降 | 近似非常准确,理想情况 | |
| 实际下降远小于预期 | 近似过于乐观,步长可能太大 | |
| 代价反而增大了 | 近似完全不准,必须缩小步长 | |
| 实际下降超过预期 | "运气好",但 太大说明模型不准 |
接受条件
本项目的接受条件(与论文一致):
其中 ,(配置项 line_search_accept_lower/upper)。
这个区间非常宽松: 极小意味着"只要代价确实下降了一点点就行"; 意味着"实际下降是预期的 10 倍以内都可接受"。实践中几乎等价于"代价下降了就接受"。
如果不接受,缩小步长重试:(,即每次减半)。
3.6.6 Forward Pass 完整流程
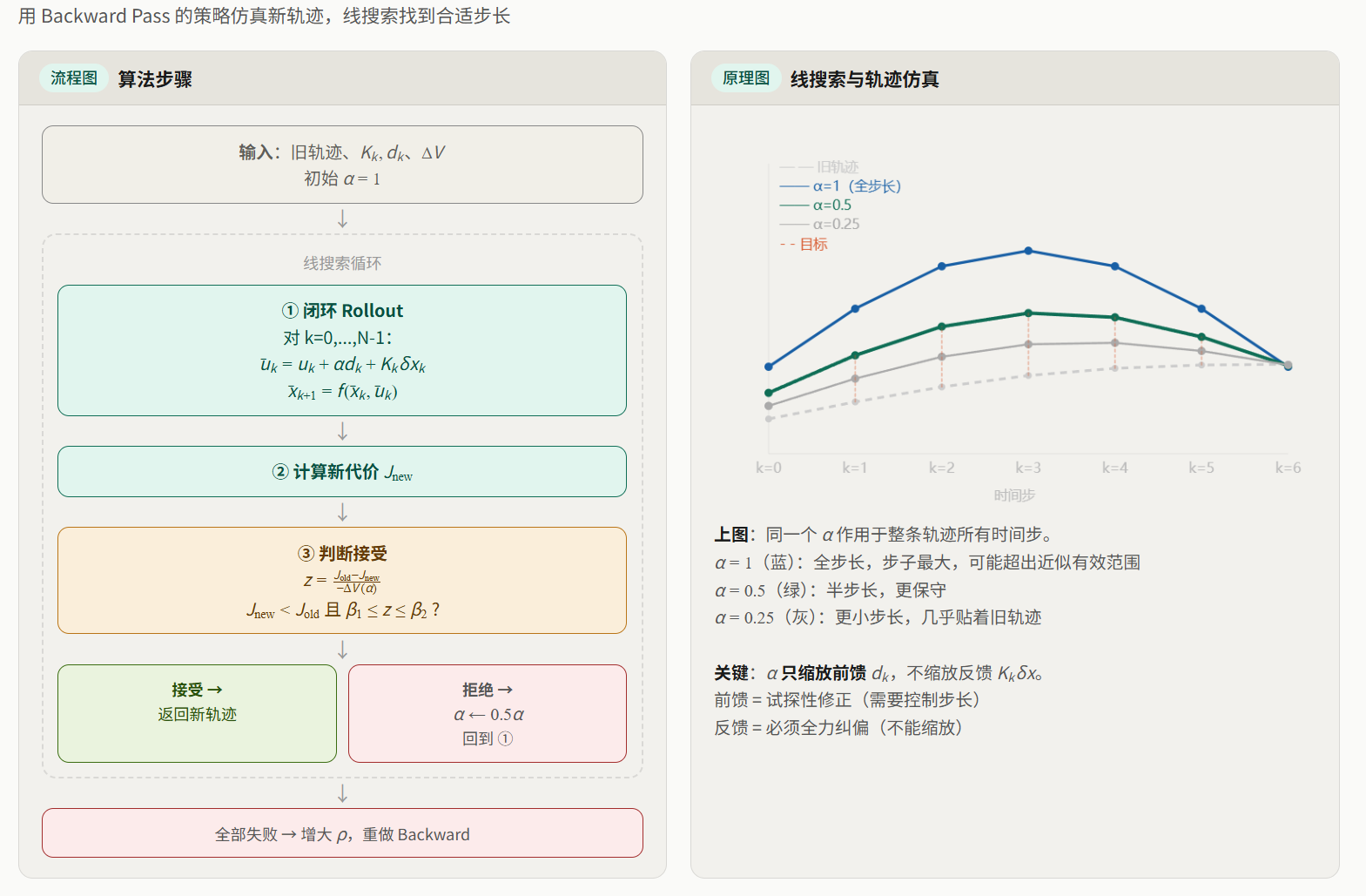
3.6.7 Forward Pass 代码
bool ILQRSolver::ForwardPass(const Vector& initial_state,
const Trajectory& nominal_trajectory,
double current_cost,
double expected_linear,
double expected_quadratic,
Trajectory* accepted_trajectory,
double* accepted_cost,
double* accepted_alpha,
double* accepted_ratio) {
double alpha = 1.0;
for (int iter = 0; iter < options_.line_search_max_iterations; ++iter) {
// ═══ Step 1: 用当前 α 做闭环 rollout ═══
Trajectory candidate(problem_.StateDim(), problem_.ControlDim(), problem_.Horizon());
candidate.SetTimeStep(problem_.TimeStep());
candidate.State(0) = initial_state;
for (int k = 0; k < problem_.Horizon(); ++k) {
const Vector dx = candidate.State(k) - nominal_trajectory.State(k); // δx_k
candidate.Control(k) = nominal_trajectory.Control(k)
+ alpha * feedforward_terms_[k] // α · d_k (前馈,受步长控制)
+ feedback_gains_[k] * dx; // K_k · δx (反馈,不受步长控制)
candidate.State(k + 1) =
problem_.Dynamics().NextState(candidate.State(k), candidate.Control(k), problem_.TimeStep());
}
// ═══ Step 2-3: 计算代价和 ratio ═══
const double candidate_cost = EvaluateTrajectoryCost(candidate);
const double actual_decrease = current_cost - candidate_cost;
const double expected_decrease = -(alpha * expected_linear + alpha * alpha * expected_quadratic);
// ═══ Step 4: 判断是否接受 ═══
if (expected_decrease > 0.0) {
const double ratio = actual_decrease / expected_decrease;
const bool acceptable_ratio = options_.line_search_accept_lower <= ratio &&
ratio <= options_.line_search_accept_upper;
if (candidate_cost < current_cost && acceptable_ratio) {
*accepted_trajectory = candidate; // 接受这条新轨迹
*accepted_cost = candidate_cost;
*accepted_alpha = alpha;
*accepted_ratio = ratio;
return true;
}
}
alpha *= options_.line_search_decrease_factor; // 步长减半,重试
}
return false; // 所有步长都试过了,全部失败
}与 LQR forward simulate 的对比:LQR 的 forward simulate(Chapter 2 §2.6)就是一个简单的 for 循环:,。没有 ,没有重试,没有代价检查——一次走完就是最优的。iLQR 的 forward pass 把这个简单循环包裹在线搜索的外层循环中,用不同的 反复尝试,直到找到一个真正让代价下降的步长。
3.7 正则化策略
在 §3.5.7 中,我们已经解释了正则化在单次 backward pass 中的作用:给 加上 确保正定可逆。本节关注的是跨迭代的问题—— 怎么随着算法运行自动调整?
3.7.1 什么是正则化?
"正则化"是优化领域的一个通用概念,核心思想是:当原问题不好解(不稳定、不唯一、病态)时,人为加入一个额外项让问题变得好解。
在 iLQR 中,backward pass 需要对 求逆来计算增益 和 。但 可能不正定(§3.5.7 详细解释了原因),导致求逆失败或得到错误方向。正则化的做法是:
把 的所有特征值都"垫高"了 ,保证了正定性。
的大小决定了算法的"性格":
| 的大小 | 算法行为 | 类比 |
|---|---|---|
| ,完全信任二阶信息,Newton 法 | 老司机飙车:快,但弯道可能翻车 | |
| 适中 | 在 Newton 和梯度下降之间折中 | 正常驾驶 |
| ,忽略曲率,退化为梯度下降 | 新手慢慢开:安全,但很慢 |
3.7.2 为什么 LQR 不需要正则化?
在 LQR 中,。其中 (问题假设)且 ,所以 天然正定,Cholesky 分解永远不会失败。
iLQR 中 的两项( 和 )都是数值计算的,而且依赖当前轨迹——轨迹越差,近似越不准, 越可能不正定。
3.7.3 自适应调整策略
不是一个固定常数,而是随着算法运行自动调整的。原则很简单:进展顺利就大胆一点(减小 ),遇到困难就保守一点(增大 )。
具体来说, 会在三种情况下变化:
情况 1:Backward pass 失败(Cholesky 分解发现 仍不正定) → 说明当前 还不够大,增大 后重试。
情况 2:Forward pass 失败(线搜索尝试了所有 都没有降低代价) → 说明 backward pass 算出的方向不好,可能是因为 太小导致 Newton 步不可靠。增大 后整个 backward + forward 重来。
情况 3:Forward pass 成功(找到了代价更低的新轨迹) → 说明当前策略有效,下一轮可以更大胆一点,减小 。
ρ 的自适应调整:
Backward Pass
│
├── 失败 (Quu+ρI 不正定)
│ └→ ρ = ρ × 10 ← 增大正则化
│ └→ 重试 Backward Pass
│
└── 成功
│
▼
Forward Pass (线搜索)
│
├── 失败 (所有 α 都不行)
│ └→ ρ = ρ × 10 ← 增大正则化
│ └→ 重新做 Backward + Forward
│
└── 成功 (找到更好的轨迹)
└→ ρ = ρ / 10 ← 减小正则化,下一轮更大胆
如果 一路增大直到超过上限(regularization_max = 1e6),说明问题实在太难了,算法放弃优化,返回当前最好的轨迹。
代码实现:
// 成功时减小正则化(更信任 Newton 步)
regularization = std::max(options_.regularization_min,
regularization / options_.regularization_decrease_factor);
// 失败时增大正则化(退向梯度下降)
regularization *= options_.regularization_increase_factor;
if (regularization > options_.regularization_max) {
return trajectory; // 正则化已达上限,放弃继续优化
}对应配置项(include/ilqr/ilqr_solver.hpp):
| 配置项 | 默认值 | 含义 |
|---|---|---|
regularization_init | 初始 ,非常小,默认信任 Newton | |
regularization_min | 下限,不让 降到零 | |
regularization_max | 上限,超过就放弃 | |
regularization_increase_factor | 失败时 乘以此因子 | |
regularization_decrease_factor | 成功时 除以此因子 |
3.8 iLQR 主循环
前面几节分别讲解了 iLQR 的四个组件(展开、backward pass、forward pass、正则化),现在把它们组装在一起,看完整的主循环如何工作。
3.8.1 主循环的输入和输出
输入:
├─ initial_state: 初始状态 x₀(固定不变)
└─ initial_controls: 初始控制序列 {u₀, u₁, ..., u_{N-1}}
(可以是全零、匀速、或其他启发式猜测)
输出:
└─ 优化后的轨迹: {x₀, x₁, ..., x_N} 和 {u₀, u₁, ..., u_{N-1}}
(在无约束代价函数下尽可能最优的轨迹)
与 LQR 的对比:LQR 的 Solve() 不需要初始控制序列——因为 Riccati 递推直接算出了全局最优增益。iLQR 需要一条"起点轨迹"来做第一次 Taylor 展开(近似必须有一个展开点)。初始猜测的质量会影响收敛速度,但通常不影响最终结果(只要代价函数没有太多局部极小值)。
3.8.2 主循环结构:双层嵌套
iLQR 的主循环有两层嵌套:
- 外层
for循环:控制最大迭代次数,每次迭代尝试找到一条更好的轨迹。 - 内层
while循环:在单次迭代内,如果 backward 或 forward 失败,增大正则化后重试,直到成功或放弃。
Solve() 的执行流程:
Step 0: Rollout
┌──────────────────────────────────────────────────────┐
│ 用 initial_controls 做前向仿真,得到初始轨迹 │
│ x₀ →[u₀]→ x₁ →[u₁]→ x₂ → ... → x_N │
│ 计算初始代价 J₀ │
└──────────────────────────────────────────────────────┘
│
▼
外层循环 iter = 0, 1, 2, ... (最多 max_iterations 次)
┌──────────────────────────────────────────────────────┐
│ │
│ 内层循环 (直到 accepted = true 或 ρ 超限): │
│ ┌────────────────────────────────────────────────┐ │
│ │ ① UpdateExpansions: 在当前轨迹处计算 │ │
│ │ A_k, B_k, ℓ_x, ℓ_u, ℓ_{xx}, ℓ_{ux}, ℓ_{uu} │ │
│ │ │ │
│ │ ② BackwardPass: 递推求 K_k, d_k │ │
│ │ ├─ 失败 → ρ ↑, 回到 ① │ │
│ │ └─ 成功 → 继续 │ │
│ │ │ │
│ │ ③ ForwardPass: 用 K_k, d_k 仿真 + 线搜索 │ │
│ │ ├─ 失败 → ρ ↑, 回到 ① │ │
│ │ └─ 成功 → 更新轨迹, ρ ↓, accepted = true │ │
│ └────────────────────────────────────────────────┘ │
│ │
│ ④ 收敛检查: |J_old - J_new| < cost_tolerance? │
│ ├─ 是 → 退出外层循环 │
│ └─ 否 → 继续下一轮迭代 │
└──────────────────────────────────────────────────────┘
│
▼
返回最终轨迹
3.8.3 主循环完整代码
Trajectory ILQRSolver::Solve(const Vector& initial_state,
const std::vector<Vector>& initial_controls) {
// ═══ Step 0: 初始 Rollout ═══
Trajectory trajectory = problem_.Rollout(initial_state, initial_controls);
cost_history_.push_back(EvaluateTrajectoryCost(trajectory));
double regularization = std::max(options_.regularization_init, options_.regularization_min);
// ═══ 外层循环:每轮尝试找到一条更好的轨迹 ═══
for (int iter = 0; iter < options_.max_iterations; ++iter) {
const double previous_cost = cost_history_.back();
bool accepted = false;
// ═══ 内层循环:失败则增大 ρ 重试,直到成功或放弃 ═══
while (!accepted) {
// ① 展开
UpdateExpansions(trajectory);
// ② Backward Pass
double expected_linear = 0.0, expected_quadratic = 0.0;
bool backward_ok = BackwardPass(trajectory, regularization,
&expected_linear, &expected_quadratic);
if (!backward_ok) {
regularization *= options_.regularization_increase_factor; // ρ ↑
if (regularization > options_.regularization_max) return trajectory;
continue; // 回到 ①
}
// ③ Forward Pass
Trajectory accepted_trajectory(problem_.StateDim(), problem_.ControlDim(), problem_.Horizon());
double accepted_cost, accepted_alpha, accepted_ratio;
accepted = ForwardPass(initial_state, trajectory, previous_cost,
expected_linear, expected_quadratic,
&accepted_trajectory, &accepted_cost,
&accepted_alpha, &accepted_ratio);
if (accepted) {
trajectory = accepted_trajectory;
cost_history_.push_back(accepted_cost);
regularization = std::max(options_.regularization_min,
regularization / options_.regularization_decrease_factor); // ρ ↓
} else {
regularization *= options_.regularization_increase_factor; // ρ ↑
if (regularization > options_.regularization_max) return trajectory;
}
}
// ④ 收敛检查
if (std::abs(previous_cost - cost_history_.back()) < options_.cost_tolerance) {
break;
}
}
return trajectory;
}
3.8.4 终止条件
iLQR 在以下三种情况下停止:
| 终止条件 | 含义 | 代码 |
|---|---|---|
| 代价收敛 | 连续两轮代价变化小于 cost_tolerance | abs(J_old - J_new) < 1e-6 |
| 迭代上限 | 达到最大迭代次数 | iter >= max_iterations (50) |
| 正则化上限 | 增大到上限仍无法成功 | regularization > 1e6 |
前两种是正常退出,第三种说明问题可能太难(高度非线性或初始猜测太差)。
3.9 本章小结
从 LQR 到 iLQR 的五个关键扩展
回顾本章开头的对比表,我们可以把 LQR → iLQR 的所有差异归结为五个关键扩展,每个扩展都有清晰的因果链:
扩展 1: 非线性动力学
└→ 需要在每次迭代时对动力学做局部线性化 (§3.4.1)
└→ A_k, B_k 不再是常量,而是每次迭代重新计算
扩展 2: 一般代价函数
└→ 代价展开存在一阶项 ℓ_x, ℓ_u (§3.4.2)
└→ 值函数出现线性项 p_k (§3.3)
└→ Q_u ≠ 0
└→ 出现前馈项 d_k = -Quu⁻¹ Qu (§3.5.6)
扩展 3: 数值不稳定性
└→ 数值计算的 Quu 可能不正定 (§3.5.7)
└→ 需要正则化 Quu + ρI
└→ 需要自适应 ρ 调整策略 (§3.7)
扩展 4: 局部近似有效范围有限
└→ 大步长可能走出近似有效范围 (§3.6.3)
└→ 需要线搜索控制 α (§3.6.5)
└→ 需要期望下降量 ΔV 来判断步长质量
扩展 5: 需要迭代
└→ 一次近似求解不够,需要在新轨迹上重新展开 (§3.8)
└→ 外层迭代循环 + 收敛检查
核心收获
- iLQR = 迭代地在当前轨迹处做局部 LQR。如果你理解了 LQR,那么 iLQR 只是多了"展开→求解→更新→重复"这个外层循环。
- 前馈项 是 LQR 和 iLQR 最本质的数学差异,它来自代价展开的线性项 。
- 正则化确保数值稳定( 正定),线搜索确保每步都在下降——这两者都是非线性问题带来的额外挑战。
从 iLQR 到 AL-iLQR:下一步是什么?
本章实现的 iLQR 能求解无约束最优控制问题,但现实中的系统总存在约束——方向盘有最大转角、车辆不能偏出车道、不能撞到障碍物。iLQR 本身无法处理这些约束。
后续三章将解决这个问题:
- Chapter 4(约束建模):如何用统一的数学形式描述各种等式/不等式约束。
- Chapter 5(增广拉格朗日方法):核心思想——把约束"塞进"代价函数中,通过拉格朗日乘子 和惩罚参数 让违反约束变得"很贵",从而把带约束问题转化为一系列无约束子问题。
- Chapter 6(AL-iLQR):把 Chapter 5 的增广拉格朗日包裹在 iLQR 外面,形成双层循环——外层更新 ,内层用 iLQR 求解无约束子问题——这就是完整的 AL-iLQR 求解器。
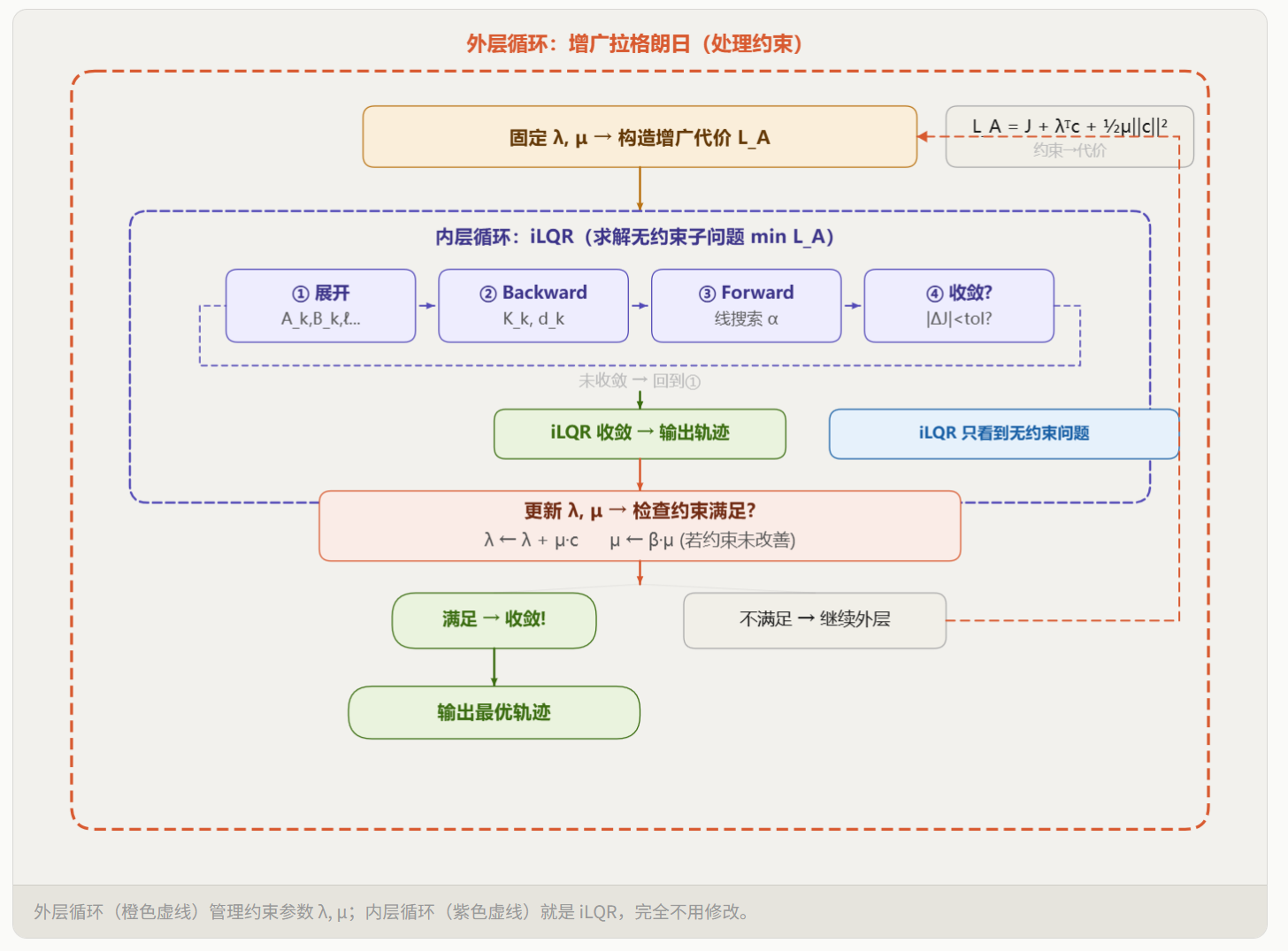
这个架构的精妙之处在于:本章实现的 iLQR 求解器完全不需要修改。约束处理完全由外层的增广拉格朗日框架负责——它只是把约束信息"包装"进代价函数,然后交给 iLQR 求解。iLQR 自始至终只看到一个无约束问题。
评论
加入讨论
登录或注册后即可发表评论,与其他学习者交流
0 条评论
加载评论中...